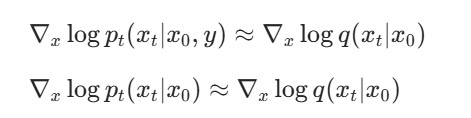Classifier-free Guidance
2025年9月15日
15:26
初次接触扩散模型时,我们通常首先学习前向过程(从图像到噪声)和后向过程(从噪声到图像)。前向过程的图像通常是由噪声生成的,无需任何特定条件。然而,我们常常希望控制生成的图像,例如只生成狗或猫。
在这种情况下,我们需要引入条件控制 text condition y,这需要理解分类器引导和无分类器引导。
Classifier Guidance
从score function的角度,未引入 条件控制之前,我们需要学习每一步的score function,,引入条件控制之后,score function变成了

利用贝叶斯公式,可以分为两项,

上面的score funtion是推理时的score function的公式,由两项组成,一个是原始的score
funtion ,第二项是,这一项即classifier对输入x的梯度(而不是对classifier 参数的梯度)
similar to how gradient back-propagation is done during classifier model training, we calculate the gradient. The difference is that, while training a classifier model requires obtaining gradients of the weight parameters for updating via gradient descent, here we only need to retain the gradient with respect to the ‘input’.
此外,还可以通过引入超参数控制classifier guaidance的强度

Classifier Guidance 的核心是:通过一个额外训练的分类器,将 “类别信息” 注入扩散模型的去噪过程。具体来说,它利用贝叶斯公式将 “有条件 score”(给定类别y时的去噪梯度)分解为 “无条件 score”(无类别约束的去噪梯度)和 “分类器梯度”(类别对噪声样本的判别梯度)的组合,从而在推理时实现类别引导。
训练阶段的 score function
Classifier Guidance 的训练过程涉及两个独立的模型:
- 扩散模型(去噪网络):仅训练其拟合无条件 score,即,扩散模型的训练目标与普通扩散模型一致(仅拟合去噪所需的无条件梯度)。

- 分类器(Classifier):单独训练一个分类器,目标是拟合类别后验概率(p(y|x_t))。分类器的输入是噪声样本x_t和时间步t,输出是类别y的对数概率。训练目标通常是交叉熵损失(在带噪样本上预测真实类别y)。
因此,训练阶段的 score function 是分离的:
- 扩散模型的
score function 仅包含无条件项,不涉及分类器;

- 分类器的训练目标是拟合\(\log p(y|x_t)\),其梯度是在推理阶段才会被使用的
“额外信息”,不参与扩散模型的训练。

关键结论
- 训练与推理的 score function 不一致:
- 训练阶段:扩散模型仅学无条件 score\(\nabla_x \log p_t(x_t)\),分类器单独学\(\log p(y|x_t)\),两者无交叉;
- 推理阶段:引导 score 是两者的组合(无条件 score + 分类器梯度 × 权重)。
- 推理阶段必须依赖分类器的梯度: Classifier Guidance 的核心是通过分类器提供的\(\nabla_x \log p(y|x_t)\)引入类别信息,因此推理时必须调用训练好的分类器,计算其对当前噪声样本\(x_t\)的梯度。
Classifier-free Guidance
Classifier-Free Guidance的核心是通过一个隐式分类器来替代显示分类器,而无需直接计算显式分类器及其梯度。
还是利用贝叶斯公式,score function可以写成下图的形式

上图也是推理时的score function,在训练阶段,
CFD 训练的核心是:让模型在同一网络中,通过 “随机切换条件输入(y 或 空)”,同时拟合有条件去噪 score和无条件去噪 score。

但是,不论是有条件场景还是无条件场景,神经网络需要拟合的都是第t步时的score function(或者说是第t步时的噪声),二者的拟合目标是一致的,