GBDT
2025年9月24日
9:51
GBM (gradient boosting machine)是一种框架,其中的模型可以用树模型、线性模型,,,都可以,但需要是弱学习器。
首先,需要定义一个损失函数L(y,y'),y'是预测值,y是真实值 ,要求这个损失函数L对y'可导,
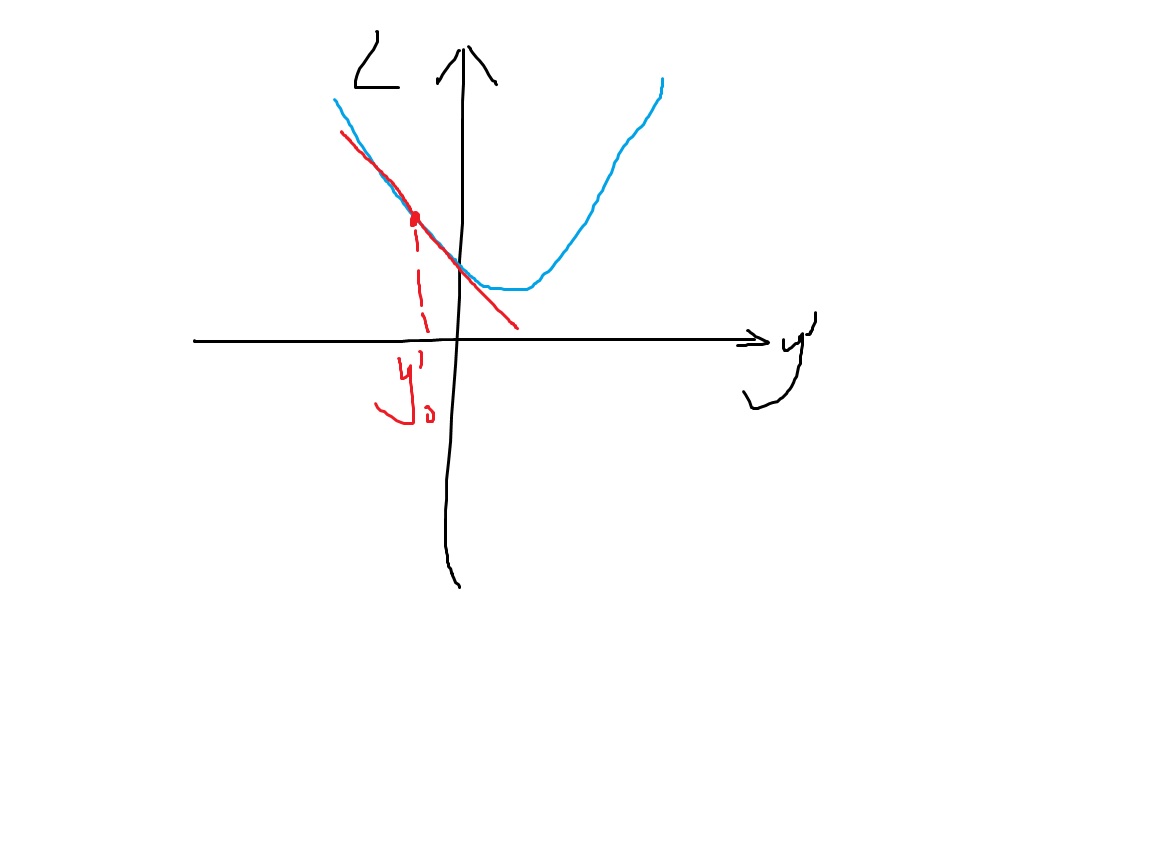
在刚开始,我们有一个初始模型,它的预测值是y'_0,也就是我们现在的位置是在y'_0。我们可以求得损失函数在y'_0处的导数,然后让y'朝着负梯度的方向移动一点,这样就可以让损失变小了。这就是GBM的思想。
相比于神经网络,神经网络也是有一个损失函数L(y,y'),神经网络的y'相当于最后一个神经元的输出。其实神经网络和GBM的目标是一样的,都是让y'朝着负梯度的方向慢慢移动,让损失函数变小。
区别在于神经网络通过调整网络参数W,W=W+lr*ΔW,让y'朝着负梯度的方向移动,而GBM通过直接对y'加入一个新的值,这个新的值就是梯度方向,也是新一轮弱学习器需要拟合的目标,来直接改变y’。
A tree has two parts, tree structure(use what features and values to split at each node ) and the value of the leaf nodes.
According to the GBDT algorithm, GBDT fits the negative gradients of loss function L with **cart regression tree(which use mse loss)** no matter it's a GBDT classifier or a GBDT regressor. After fitting a regression tree, **we can make a little refinement by keeping the tree sturcture while recalculate the value of the leaf nodes to minimize the loss**
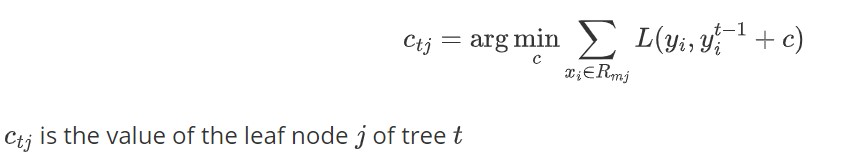
也就是说,对于GBDT来说,不论是分类任务还是回归任务,每个y'都是一个CART回归树(因为要拟合梯度,梯度是连续值,所以是回归树)。那么得到新的y'这棵CART树之后 ,这棵树的叶子节点的输出值c_tj,是使得梯度mse最小的值,但是这个值是叶子节点所有可能的输出值中,让整体loss最小的那个值吗,不一定!因为最小化梯度mse,并不等价于整体Loss最小,只能保证loss朝着减少的方向变化。此时,我们需要保持树的结构不变,重新计算让loss最小的叶子节点的输出值。
xgboost就解决了这个问题,直接将叶子节点的最优输出值与loss损失函数关联了起来!!!!!!
GBDT能保证,加入新的y’这棵树后,这棵树的叶子节点的输出值能让整体损失降低;而XGB能保证,加入新的y’这棵树后,这棵树的叶子节点的输出值,在Δ这个小范围内(泰勒展开的定义),能让整体损失最低。