Basic_2
2025年10月30日
19:48




★关于Normalize 数据(其实是Standardization)
即0均值化,和方差归一,然后用训练集上的均值和方差,normalize test set.
为什么需要Normalization?
The intuition that cost function will be more round(the contour is circular rather than ellipse), and easier and faster to optimize when features are all on similar scales. 椭圆的切线的垂线(即梯度的方向)并不是指向中心那个红点的(局部最小),而圆的切线的垂线(即梯度的方向)始终指向中心那个红点的(局部最小),因此,对于contour是圆的loss超曲面来说,gradient descent需要的步数更少,优化更快。
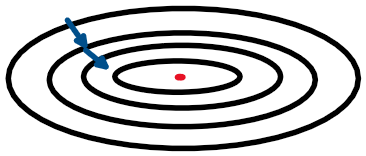
![什么时候需要Normalization?
当features之间的scale差别很大时 ,比如x1~[0,1], x2~[1,10000],当相差不大时,比如x1~[0,1], x2~[1,2],可以不Normalize。
Standardization 对outliers不敏感,Normalization是对特征的norm进行归一化,如min max scaler,适用于基于距离的算法。
★关于梯度消失和爆炸
假设网络有100层,第10-100层的权重W的模都大于1,相当于前10层的W被后90层的W逐层放大,类似于x乘以10000,此时x变化很小,放大10000倍后的变化很大,也就是梯度爆炸;同理,当第10-100层的权重W的模都小于1,相当于前10层的W被后90层的W逐层缩小,类似于x乘以1e-10,此时x的变化对y几乎 没有影响,也就是梯度消失。
可以通过初始化权重来缓解梯度消失和爆炸,使得梯度不会消失或爆炸地 too quickly. 有多种初始化方法,基本可以分为均匀分布和正态分布,正态分布的均值通常为0,方差可以是1,也可以是constant/n ,constant可以是1、2、6等,n是权重矩阵W的元素个数,或者是这一层的神经元个数。
★关于mini batch
Mini batch 的Loss曲线是振荡的,因为每个batch的数据是不同的,而且batch中有noise,用当前batch计算得到的梯度去更新参数,得到的参数在下一个batch上的loss可能会增加。
墨迹绘图
墨迹绘图](Basic_2.files/image007.png)

★指数加权平均
,展开就是指数形式,相当于越靠近当前t的权重越大,越远离当前t的权重越小,且呈指数递减。v_t大概是1/(1-)天的平均,再往前权重就特别小了。![]()
为什么用,而不是直接计算10个时间步的均值?因为后者需要记录10个时间步的每个值,也就是10个值,而移动平均只需要记录v_t一个值就可以,节省存储空间,且计算效率更高。Especially
when you need to compute the averages of lots of variables, 移动平均的空间和时间效率都更高。![]()
Bias estimation:,在初始化阶段,v_t的值很小,尤其当的值很大时,需要很长个t。因此做出改进,,当t很小时,将v_t放大,当t很大时,几乎不改变原来的v_t。![]()
★Momentum gradient descent
就是对梯度进行指数加权平均,通过对历史梯度的平均,如果梯度在某个方向上振荡,那么通过平均可以减小振荡,如果梯度在某个方向上保持,那么通过平均还会使梯度保持在这个方向,达到加速收敛的效果。
Momentum梯度下降时一般不需要做Bias estimation修正,因为相当于warm-up了。
两个版本:
没啥大的区别,区别在于学习率不同罢了,不乘以,梯度的值会大一些,学习率就相应小一些罢了。![]()
★RMSprop
历史梯度平方的加权平均,然后用这个sqrt(加权平均值)对最新的梯度进行缩放,值越大,步长越小。RMSprop类似于Momentum,同样可以消除振荡。
★Adam
在更新梯度时,Momentum相当于用历史梯度的加权平均替换了当前梯度,Rmsprop相当于用历史梯度平方的加权平均值对当前梯度进行缩放,而Adam结合了momentum 和Rmsprop。
4个超参数


★超参数搜索
不要用grid
search(原因是很费时间,而且不同超参数的重要性不一样,grid search会浪费很多时间在不重要的超参数上),用random search代替,random不是均匀的random,需要scale search,如学习率的搜索范围是[0.001,1],应该在[0.001,0.01]、[0.001,0.1]、[0.1,1]这三个区间内random搜索。为什么要这种指数式地搜索而不是直接在[0.0001,1]区间上线性搜索,原因是超参数对网络的影响不是线性的,比如Momentum中的,从0.9000增加到0.9005,意味着从计算历史10个batch的梯度平均值增加到计算历史10.05个batch的梯度平均值,而当从0.999增加到0.9995,意味着从计算历史1000个batch的梯度平均值增加到计算历史2000个batch的梯度平均值。
★关于标准化和归一化
Standardization of datasets is a common requirement for many machine learning estimators implemented in scikit-learn; they might behave badly if the individual features do not more or less look like standard normally distributed data: Gaussian with zero mean and unit variance.
Centering and scaling happen independently on each feature by computing the relevant statistics on the samples in the training set. Mean and standard deviation are then stored to be used on later data using transform.
Normalization is the process of scaling individual samples to have unit norm. This process can be useful if you plan to use a quadratic form such as the dot-product or any other kernel to quantify the similarity of any pair of samples.
来自 <https://scikit-learn.org/stable/modules/preprocessing.html#normalization>
也就是说,standardization是按列进行,每个特征的均值为0,方差为1。Normalization是按行进行,每个样本的norm是1。
★关于Batchnorm
Intuition:不能只对输入x做0均值和方差1的操作,也需要对中间隐藏层的神经元做相应的操作,在输入激活函数之前做batchnorm,并引入两个可学习参数对其进行缩放平移。
在引入Batchnorm层后,该层神经元的偏置项z=wx+b中的b可以不要,因为无论b是多少,batchnorm都会把z的均值变为0。
batchnorm好处:
- 前面层的输出变得稳定,也就是后面层的神经元的输入变得稳定,训练起来更加容易。
- 无论前面几层的神经元输出如何变化,都不会对本层的z造成太大影响,因为z始终是均值0方差1,并且batchnorm的两个可学习参数也不依赖于前面层,减弱了后面层对前面层的依赖,使得各个层相对独立一些。
batchnorm有轻微的正则化作用,因为batcnorm在每个batch上计算均值方差,而不是在整个数据集上计算均值方差,这就相当于在每个神经元上引入了noise,既引入了加性noise(减去均值),有引入了乘性noise(除以标准差),对于batchnorm来说,batch size越大,正则作用越小。类似于dropout,dropout也相当于在每个神经元上引入了乘性噪声(乘以1或者乘以0)。引入噪声就会起到正则作用 preventing the model from fitting training data too closely and acting as a form of regularization.
Batchnomr对batchsize敏感。