Let's build the GPT Tokenizer
2025年5月29日
17:39
Tokenizer is a completely separate object from LLM.
Tokenization 是LLM的基础,很多LLM的问题其实跟tokenization有关。
Tokenization is at the heart of much weirdness of LLMs. Do not brush it off.
- Why can't LLM spell words? Tokenization.

同样的Egg,但是有不同的token。
而且有些token的长度特别长,例如.DefaultCellStyle
- Why can't LLM do super simple string processing tasks like reversing a string? Tokenization.
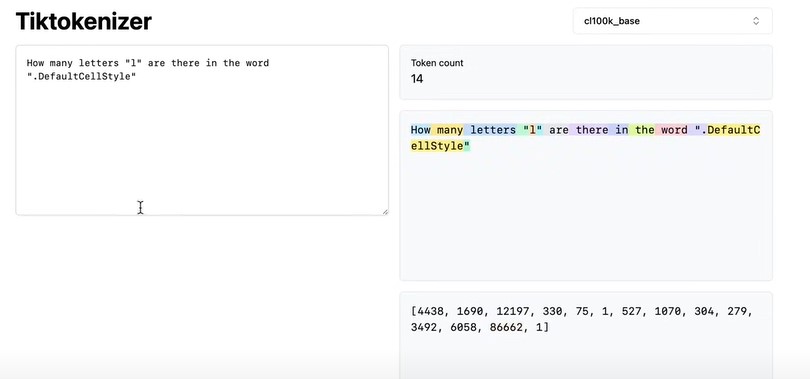
让LLM数.DefaultCellStyle有几个字母l,由于.DefaultCellStyle整个被分为一个token,所以LLM很难回答正确。
同时,让LLM将.DefaultCellStyle倒序输出,LLM也无法完成。
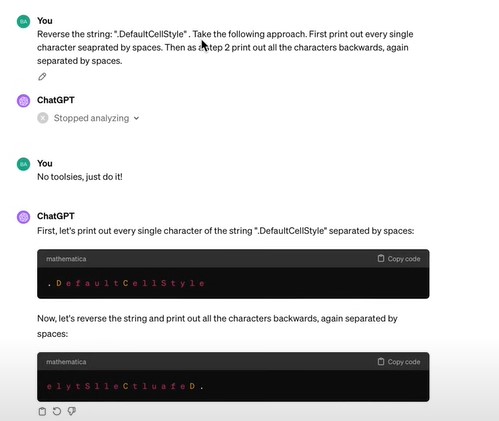
倒序输出可以通过先让LLM用空格分隔,再倒序输出。(这个思想,比如few shot prompt, think step by step等技巧,都是想方设法让LLM能输出我们想要的答案。)
- Why is LLM worse at non-English languages (e.g. Japanese)? Tokenization.


- 同样的一句话,翻译成英文和中文,英文经过分词后的token要少于中文的token,也就是中文的序列长度要更长,而Transformer的输入序列是有限的,因此,假设Transformer输入序列长度是1024,对于英文来说,1024个英文token能表达的话要比1024个中文token能表达的多。
- tokenizer的训练数据,英文的数据更多。
- Why is LLM bad at simple arithmetic? Tokenization.

一个数具体是被tokenize成几部分,是非常不确定的,取决于tokenizer训练时的数据。sentencepiece可以将所有数字先全部分开,从而避免这个问题。
- Why did GPT-2 have more than necessary trouble coding in Python? Tokenization.

python代码中有很多缩进,即空格符,每个空格都是一个token,这会极大地浪费Transformer的context length.
- Why did my LLM abruptly halt when it sees the string "<|endoftext|>"? Tokenization.
这个例子好搞笑^_^

- What is this weird warning I get about a "trailing whitespace"? Tokenization.
GPT的很多token是以空格开始的,例如假设How are you? Oh my god. 这句话出现在训练数据中,经过tokenize之后,空格+O是一个token,而不是O是一个token,如果用户输入How are you?+空格,那么就会和训练数据的分布不一致(训练数据的分布是How are you?后面接“空格+O”这个token,而用户的输入是How are you?+空格,也就是说LLM没有在训练数据中见过。)
- Why the LLM break if I ask it about "SolidGoldMagikarp"? Tokenization.
- Why should I prefer to use YAML over JSON with LLMs? Tokenization.
- Why is LLM not actually end-to-end language modeling? Tokenization.
- What is the real root of suffering? Tokenization.
关于vocab size的问题,vocab size越大,同样的一段话,经过分词处理后的token越少,Transfomer就可以关注更多的内容,但是token embedding的长度也会增加,导致最后softmax层的计算量增加。
每个字符character都有一个Unicode,字符串可以通过utf-8编码,即只用8位数来进行表示。
>>> s = "i love djfsj sdjfklowe,是槈未经对方是否"
>>> list(s.encode('utf-8')) #uft-8编码,最大的数256,编码后的list长度要大于等于用unicode表示的list长度
[105, 32, 108, 111, 118, 101, 32, 100, 106, 102, 115, 106, 32, 115, 100, 106, 102, 107, 108, 111, 119, 101, 239, 188, 140, 230, 152, 175, 230, 167, 136, 230, 156, 170, 231, 187, 143, 229, 175, 185, 230, 150, 185, 230, 152, 175, 229, 144, 166]
>>> [ord(i) for i in s] #unicode码,每个字符对应一个unicode
[105, 32, 108, 111, 118, 101, 32, 100, 106, 102, 115, 106, 32, 115, 100, 106, 102, 107, 108, 111, 119, 101, 65292, 26159, 27080, 26410, 32463, 23545, 26041, 26159, 21542]
我们不能直接用unicoder码即单个字符来表示每个token,因为这样的话,1..vocab size会很大,unicode最大是15w。2.有些character出现次数很多,而大部分character很少出现,导致计算效率低。3.经过分词后的token也很多,因为每个字母都是一个token,而transformers的输入长度是有限 的。
我们也不能直接用uft-8编码的结果来进行tokenization,因为这样的话,1.vocab size会非常小,为256。 2.经过分词后的token会非常非常多,比字母还多,因为一个字母可能被分为多个token。
Byte-pair encoding
Suppose the data to be encoded is:[8]
1)第一步
aaabdaaabac
The byte pair "aa" occurs most often, so it will be replaced by a byte that is not used in the data, such as "Z". Now there is the following data and replacement table:
2)第二步
ZabdZabac
Z=aa
Then the process is repeated with byte pair "ab", replacing it with "Y":
3)第三步
ZYdZYac
Y=ab
Z=aa
The only literal byte pair left occurs only once, and the encoding might stop here. Alternatively, the process could continue with recursive byte-pair encoding, replacing "ZY" with "X":
4)第四步
XdXac
X=ZY
Y=ab
Z=aa
This data cannot be compressed further by byte-pair encoding because there are no pairs of bytes that occur more than once.
To decompress the data, simply perform the replacements in the reverse order.
我们从utf-8编码后的结果出发,最初的vocab_size=256,然后迭代地进行这个过程。所以Byte-pair中的byte指的就是先用uft-8编码,vocab_size是256,即一个字节byte。
用于训练tokenizer的数据和训练llm的数据是不一样的,如果用于训练tokenizer的数据中japanese的数据更多,意味着更多的japanese token会被merge(因为japanese token pair的出现次数更多),那么japanese句子经过tokenize后的sequence length会更短,也就会更有利于japanese的训练(因为transformer能关注到更长的japanese句子。)
需要注意的是,不是所有的token sequence 都是有效的utf-8格式。我的理解:每个character可能会被表示成多个utf-8码,例如“好”的uft-8码是\xef\xbc\x8c “在”的uft-8码是\xe6\x96\xb9,那么如果\x8c和\xe6被merge成新的token,也就是说这个token是 \x8c\xe6,但是 \x8c\xe6这两个uft-8码,不一定符合utf-8的数据格式要求,即b' \x8c\xe6'.decode('utf-8')时会报错。 不是这样的,不可能出现 \x8c\xe6这种情况,因为\xef\xbc\x8c的出现次数一定比 \x8c\xe6多(“好”单独出现的次数一定比“好在”出现的次数多。)真正的原因是:假设某个字符的utf8是:\xef\xbc\x80,那么\x80可能成为新的token,但是\x80无法被解码。
总结:原始的vocab_size是256(其实不是256,比256要小,因为utf-8要满足一定的数据格式,如下图),例如
>>> b'\x80'.decode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte
因为\x80=10000000,不满足utf-8的数据格式要求!(如果第一位是1,第二位也要是1)

,每个token id都用一个字节表示,例如 \x8c,共16*16=256个token,经过训练后的会生成新的token,vocab_size也随之增大,新的token是原始256个token的组合,例如:
\x8c\x1c,\x82\x2c\x4c\x13,新token具体由几个原始token组合?不一定,可能是2个,可能是3个,可能是100个…….
BPE有个问题是,单词后面经常跟着标点符号,例如dog. dog? dog! 如果把dog和!连在一起作为token,那么不符合语义,所以GPT2先将句子进行正则匹配,根据正则表达式把句子分为多个chunk,对每个chunk进行统计然后合并,所以永远不会出现dog后面跟着!这种情况,因为dog和!在不同的chunk中。
import regex as re
gpt2pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
print(re.findall(gpt2pat, "Hello've world123 how's are you!!!?"))
#['Hello', "'ve", ' world', '123', ' how', "'s", ' are', ' you', '!!!?']
一个tokenizer只需要2个文件,一个vocab.json,一个merge.json,
merge.json即
X=ZY
Y=ab
Z=aa
编码时按照从下往上的顺序,解码时按照从上往下的顺序
SentencePiece
The big difference: sentencepiece runs BPE on the Unicode code points directly! It then has an option character_coverage for what to do with very very rare codepoints that appear very few times, and it either maps them onto an UNK token, or if byte_fallback is turned on, it encodes them with utf-8 and then encodes the raw bytes instead.
TLDR:
- tiktoken encodes to utf-8 and then BPEs bytes
- sentencepiece BPEs the code points and optionally falls back to utf-8 bytes for rare code points (rarity is determined by character_coverage hyperparameter), which then get translated to byte tokens.
(Personally I think the tiktoken way is a lot cleaner...)
Sentencepiece 直接对unicode code point进行BPE,也就是对按照character进行BPE,当遇到稀有的character时,if byte_fallback is turned on, 用uft-8码进行代替
SolidGoldMagikarp问题
由于用于训练tokenizer的数据集和训练 LLM的训练集是不同的,用于训练tokenizer的数据包含了reddit的数据,SolidGoldMagikarp是reddit的用户名,并且出现了很多次,因为被merge成了一个token,但是训练LLM时的数据集,从来没有出现reddit上的这个用户名,因此SolidGoldMagikarp这个token的embedding仍然是随机的,初始化的,没有训练过的,所以当用户输入和SolidGoldMagikarp相关的prompt时,LLM会失控。
Final recommendations
- Don't brush off tokenization. A lot of footguns and sharp edges here. Security issues. Safety issues.
- Eternal glory to anyone who can delete tokenization as a required step in LLMs.
- In your own application:
- Maybe you can just re-use the GPT-4 tokens and tiktoken?
- If you're training a vocab, ok to use BPE with sentencepiece. Careful with the million settings.
- Switch to minbpe once it is as efficient as sentencepiece :)