let's dive deep into chatgpt
2025年7月6日 星期日
16:59
1.对于base模型来说,如果输入wikipieda上某个词条的前几句话,base model很可能完全复述wikipieda上的内容,因为可能在这个wiki上训练了10个epoch,就像读了10遍,base模型直接把这篇文章背诵下来了。
base模型是一个token补全器,而我们需要的是助手,所以需要进行SFT。
2.关于大模型的幻觉:
模型将学到的知识存储在模型的参数中,可以把这405B(以lamma 3为例)个参数视为对互联网的压缩,这种压缩当然是有损的,大模型生成的内容仅仅是对互联网的一些回忆,所以,互联网数据中经常出现的内容,可能会被更容易记住,不能完全相信生成的内容,以为这只是对互联网文档的模糊回忆,这些内容是概率性的,统计性的。模型只是按照概率进行最佳推测。
即大模型捏造信息。
为什么会有幻觉,幻觉是从哪来的?

模型在统计上模仿训练集,比如训练集中有如上图所示的3条数据,并自信地回答了正确答案,当推理时被问一个新的不存在的人物时,模型会模仿这种回答,并给出统计上的最佳推测,结果就是编造信息。也就是,模型并不会表达出自己不知道,而是尽力模仿训练集,从而进行编造。
如何缓解?

1)在训练集中包含新的示例数据,当模型不知道示例的答案时,这些数据的答案是不知道,从而让模型能够表达出自己不知道这件事,而不是胡编乱造。现在的问题是,如何知道模型不知道这个问题的答案?Meta LLAMA3的做法是进行knowledge probe,从训练集中采样一段文字,让另一个LLM生成关于这段文字的几个QA pair,用这几个QA向LLM提问,用llm as judge进行打分,重复多次,如果LLM不知道这个答案,那么就构造一条新的数据,Q不变,A是I don’t know 等类似的refusal回答。

2)让LLM可以使用tools,可以创造一个机制,使LLM能够生成特殊的token,<search_start> <search_end>,当模型发出这个token时,会停止后续生成,并进行网络搜索,然后将检索到的文本返回给模型,拼接到context window中,然后继续生成。
现在的问题是,如何教会模型发出使用这种tool的token呢,还是通过在训练集中构建几千几万个这种数据来训练模型。
总结:当我们问LLM某个问题时,如果LLM对它的权重 、参数、激活值等有足够的信心,认为这个问题的答案可以从记忆中检索,它会直接生成答案。如果它不确定,就会使用网络搜索。对于user来说,要对自己问的问题有一个大致的判断, 这个问题是否是很清晰地容易回答的,是否能让LLM仅通过本身几百B的参数(对互联网的模糊记忆)就能正确回答的,如果不是,要进行网络搜索,来确保答案的正确性。

神经网络的参数是一种模糊的回忆,而上下文窗口是模型的工作记忆,和人类类似。上下文的数据可以被模型直接访问,它直接输入到神经网络中,而不是模糊的记忆。这对我们使用LLM也有帮助,例如,问LLM, can you summarize chapter1 of Pride and Prejudice? LLM可以很好地回答,因为LLM看过傲慢与偏见,LLM有足够的记忆。但是比起让LLM回忆,更有效的方式是直接提供给他们信息,将第一章的内容也输入到上下文窗口中,这样LLM可以直接访问他们,而不需要回忆。LLM回答的质量也会显著提高。(这和人类一样,在总结之间重新阅读了文章,会做得更好。)
3.后训练,用人类标注的多轮对话进行SFT
openai的InstructGPT,雇了几十个外包人员labelers,生成多轮对话的数据集,生成的原则大概是1)helpful,2)truthful, 3)harmless,
这些对话数据集当然无法cover所有的prompt,但是模型经过这样的helpful,truthful,harmless数据集训练之后,模型就会开始表现出这种类似的乐于助人、真实、无害的助手个性persona。
近些年,随着技术发展,更多的是使用LLM合成数据,人类进行轻微地干预,来生成数据集。Ultrachat数据集。
当你问chatgpt时,chatgpt给你回复,这些回复并不是来自什么神奇魔法AI,it's coming from something that is statistically
imitating human labels which comes from labeling instructions written by companies like openai.
问chatgpt就像在问human labeler,human labeler会说什么,it's kind of like asking what would human labeler say in this conversation.
当然这些human labelers不是一些随便的人,而是一些领域的专家。例如,当你询问代码问题时,参与代码对话数据集的human labelers是eduated expert。
4.关于LLM的自我认知

当问chatgpt,who are you ,who built you? chatgpt回答,I was built by openai based on gpt model。
这不代表LLM有自我意识,它之所以这样说,是因为它的训练数据里有大量关于此的回答。作为开发者,有2种方式可以覆盖这个标签。
1)硬编码,在SFT数据集中指定这种问题的答案。
2)system message。在上下文窗口中的不可见token, 提醒模型它的身份(用来防止客服机器人变成虚拟女友)。
5.LLM need tokens to think
当模型进行训练和推理时,是在一维token序列进行工作,是从左到右的顺序进行演变,并给出下一个token的概率。每一个token的计算量是有限的(当然输入序列越长,计算量越大,但可以忽略不计),因此,我们希望将计算分布在多个token上。知道这一点对我们训练LLM和使用LLM都有帮助。
1)训练时,下图右边的答案要好于左边,所以SFT数据集应该是右边这种数据,而不是左边的。因为左边是先直接回答,也就是在训练模型在单个token中得到答案,这是行不通的,因为每个token的计算量是有限的。而右边是让模型慢慢得出答案,也就是训练模型在多个token上分散计算,每个token上的计算都相对简单,多个token上的计算进行累加,得到最终的答案。

2)在推理时,promt中加入let's think step by step,将计算分散在更多的token上。实际上通常不需要user来显式地考虑这个问题,这个问题是openai的数据标注人员考虑的,他们确保SFT数据集中的数据是这样的就可以了,这样训练出来的LLM回答时会自动生成中间结果 ,think step by step.
PS:在现实中,这种需要数学计算或者心算的问题,通常use code来解决,而不是完全依赖LLM进行下图中的心算,这种心算不是100%可靠的,特别是当数字很大时,任何一个步骤都可能出错 。当使用代码时,就不需要依赖LLM的心算了,LLM只需要生成代码,使用python interpreter执行,得到结果,会可靠得多。
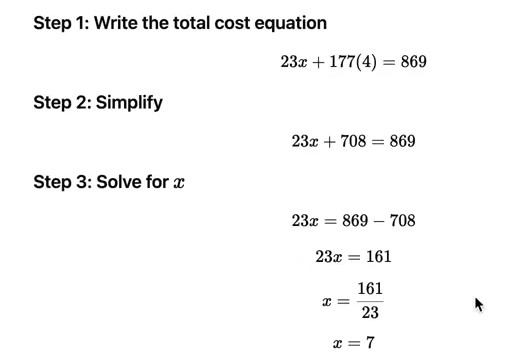
总结:LLM需要tokens to think,将计算分散到多个token上,要求模型创建中间结果 ,并尽量使用tools,而不是让模型纯粹依赖它的记忆参数来处理这一切。
LLM需要tokens to think的另一个例子是counting。如下所示,这就是让llm在单个token中完成计数这个操作。此时好的做法是让LLM用代码tool,LLM很擅长copy paste,只需要把这个字符串复制粘贴到代码中,执行,就可以得到长度了。

另一个例子是问LLM,how many 'r' in 'strawberry'?这个问题的难点有2个,一个是LLM看到的是token而不是letter,第二个是这个问题是个计数问题,计数问题是llm不擅长的,因为llm需要tokens to think。
LLM会在一些很简单的问题上出错,如认为9.11比9.9大。原因是在圣经中,章节9.11在9.9之后出现,所以模型认为9.11比9.9大。
6.强化学习

LLM的训练可以类比上学学习书本上的知识。书本上的大部分知识是阐述性的知识,exposition,就像是背景知识,当人在阅读背景知识时,可以粗略地视为在该数据上的训练,等同于LLM的预训练。书本上的第二类信息是问题及专家的解答过程,这个解答相当于LLM助手的理想回答,相当于SFT训练。书本上的第三类信息是每个章节的练习题,这部分只有问题,没有解答过程,但是有标准正确答案,这个部分相当于强化学习,自己尝试不同的解决方法,并观察哪些方法能达到最终正确答案。
为什么需要强化学习?
1)

当构建SFT数据集时,如上图所示,有4种response,4个response的答案都是正确的3,但是具体选择哪种response作为SFT的训练数据呢,是不确定的,因为我们和LLM的思考方式不同,我们的知识和LLM不同,LLM可能认为某种response是trivial的,过长的response仅仅是浪费token,也可能认为某种response是它不曾掌握的知识,这种response会让它感到困惑。我们并不知道最适合LLM的response 是什么,因此,我们需要允许LLM发现适用于它的response token序列,可以可靠地得到答案,此时就需要强化学习来不断试错 。如下图所示,prompt---->solution----->correct answer。prompt和correct answer是确实的,solution是要LLM自己通过试错生成的,而不是人类标注员提供。(LLM就像在游乐场玩耍,它知道要达到什么目标,它发现了适合它的response solution 序列,这个序列在统计上更平滑,充分利用了模型已有的知识)
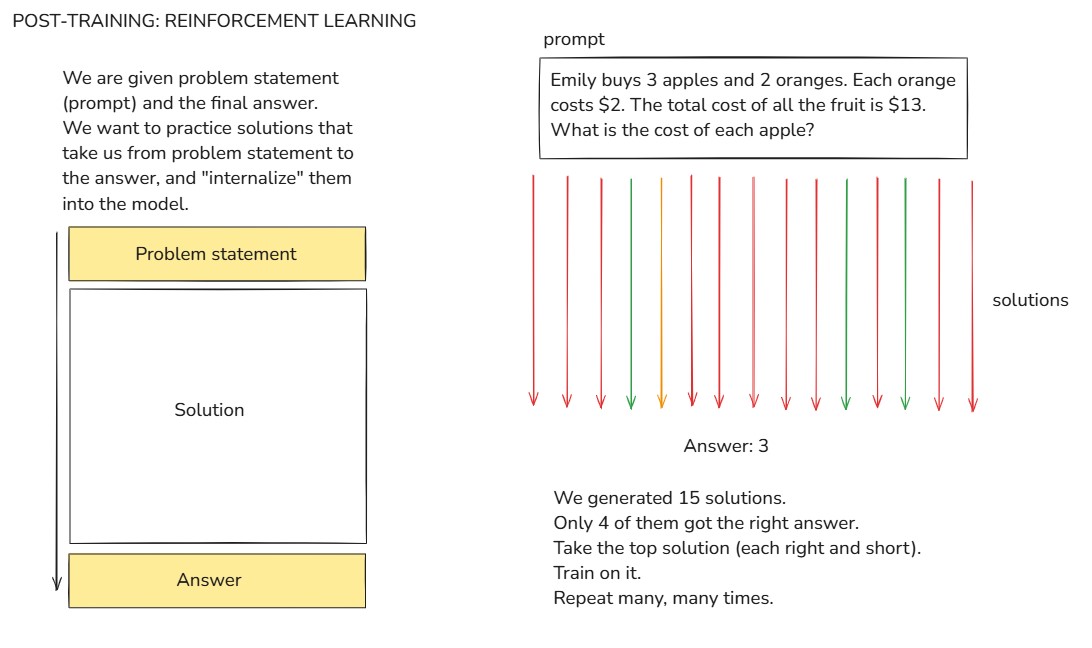
2)一味模仿无法超越,只有自己探索才能超越
监督学习是模型在模仿人类专家,但是永远无法超越顶尖专家。
Alphago超越了人类的围棋水平,例如在第37步中走了非常不同寻常的一步,人类几乎不会走的一步,这实际上是超越了人类。
同理,将强化学习应用于训练LLM,理论上LLM可以在推理或思考上超越人类。what does this mean?也许是LLM发现了一种完全不同的类比,或思考方式,或新的语言类似编程语言。
Deepseek r1
随着训练步数增加,推理准确率增加,与此同时推理的tokens序列也增加,因为LLM涌现出了类似wait, that an aha moment这种情况。模型发展了自己的认知策略,自己的思考方式,reevaluate,多方面思考,思维链,这就是导致响应长度增加的原因,同时也是提高推理准确性的原因。

RLHF
当问题没有答案时,即不可验证,如创意写作,给不同解决方法评分变得困难。
用神经网络来模拟人类偏好,即训练一个reward model。
RLHF的好处:可以在任意领域进行RL,即使是不可验证,而且empirically效果提升。
坏处:reward model是有损的,而且reward model本质上是神经网络,RL非常擅长愚弄reward model,生成对抗性样本。
因此在实际中,RLHF通常只运行几百steps,如果一直运行,就会开始愚弄reward model。而RL则可以无限运行。从这个意义上说,RLHF不是RL,而是一种微调。

PREVIEW OF THINGS TO COME
- multimodal (not just text but audio, images, video, natural conversations)
- tasks -> agents (long, coherent, error-correcting contexts)现在大多数情况是将单个任务交给模型,仍然需要我们来organize a coherent execution of tasks,模型不能修正错误,尤其是长时间运行。Agents随着时间执行任务,人类负责监督,agents偶尔会报告进展,
- pervasive, invisible
- computer-using
- test-time training?, etc.
,