bm25
2025年8月2日
10:10
tf-idf
tf:词频,一个词t在某个文章D中出现的频率,频率越高,t对D的重要性越高。

idf:逆文档频率,语料库C中出现词t的文档数越多,说明词t可能是常用词,t的重要性越低。

tf*idf,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。
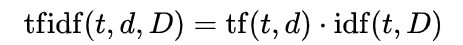
bm25
tf-idf的值和词t在d中出现的次数成正比,线性关系,假设cat在d中出现了10次,tfidf('cat',d,D)=0.2,此时令cat在d中出现20次,那么tfidf('cat',d,D)=0.4,但是词频和相关性之间的关系可能是非线性的。
query Q和文档D的相似度得分= Q中的所有token,和D的bm25分数,求和。

总结:bm25是对tf-idf的改进,tf-idf和bm25都可以用来得到文档的关键词,当然也都可以用上图中的公式来得到query Q和文档D的相似度分数。还可以通过tf-idf/bm25稀疏矩阵,通过向量相似度来计算两个文档之间或Q和D的得分。
再总结:
有2种方式计算query Q和文档 D的相似度:
1)query Q和文档D的相似度得分= Q中的所有token,和D的bm25分数/tfidf分数,求和。
2)query Q的稀疏向量,向量长度为n,为语料库中所有token的个数,向量中每个元素是token和Q的bm25分数/tfidf分数;
文档D的稀疏向量,向量长度也为n,向量中每个元素是token和D的bm25分数/tfidf分数;
然后两个向量计算相似度。
第一种方法(对 query 中所有 token 与文档的 BM25/TF-IDF 分数求和)更快,核心原因是其计算复杂度更低,且避免了稀疏向量构建与高维度匹配的额外开销,具体分析如下:
- 第一种方法:
仅需遍历 query 中的所有 token(假设 query 长度为m,通常为几个到十几个词),对每个 token 计算其在文档中的 BM25/TF-IDF 分数,最后累加求和。
计算复杂度为 O(m)(m为 query 的 token 数量),与语料库总词数(n)无关。 - 第二种方法:
需先为 query 和文档构建长度为n(语料库总 token 数,可能达数万至数十万)的稀疏向量,再计算向量相似度(如余弦相似度)。
过程包括: - 遍历语料库词表构建向量(复杂度O(n));
- 计算向量相似度时,需匹配两个向量的非零维度(即使稀疏,仍需处理词表索引映射,复杂度与n相关)。
对于抽取式问答来说,文章和问题涉及到关键词这种类型的,bm25是很适合文章和问题都有关键词的。bm25就是一种基于关键词的 算法。