[李宏毅]- 生成式AI时代下的机器学习2025-第7-8讲
2025年10月16日
11:03
第7讲-LLM推理
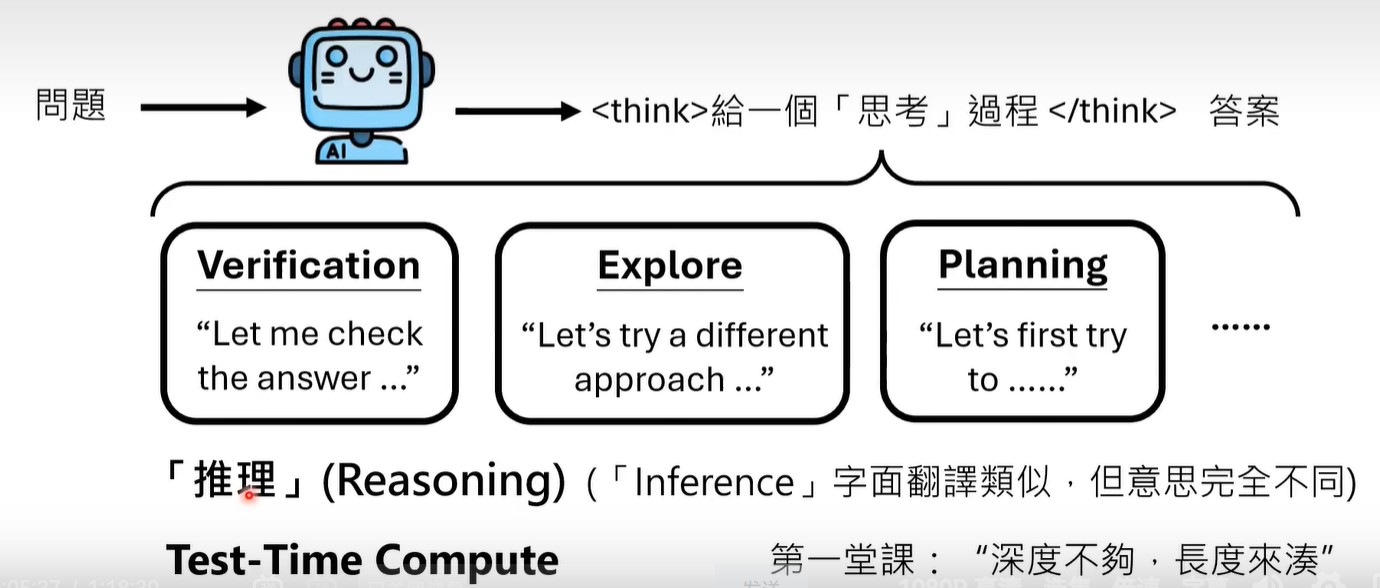
LLM推理和人类推理是不同的概念,LLM推理只是输入和答案之间的intermediate中间token,
LLM推理是一种test time compute,即在预测时进行更多的计算,来得到更好的结果。(例子就是,如果让LLM直接生成答案,答案是错误的,但是让llm think step by step(或是不用greedy decoding,而是采样更多的response),生成的 response长度虽然变长了,但答案是正确的)。
为什么test time compute有用?深度不够,长度来凑。
Scaling llm test-time compute optimally can be more effective than scaling model parameters. https://arxiv.org/abs/2408.03314
在AlphaGo中,训练结束后得到了policy network,但是test时,并不是直接使用policy network得到下一步落子位置,而是进行Morto carlo 树搜索,也就是使用了test time compute的例子。
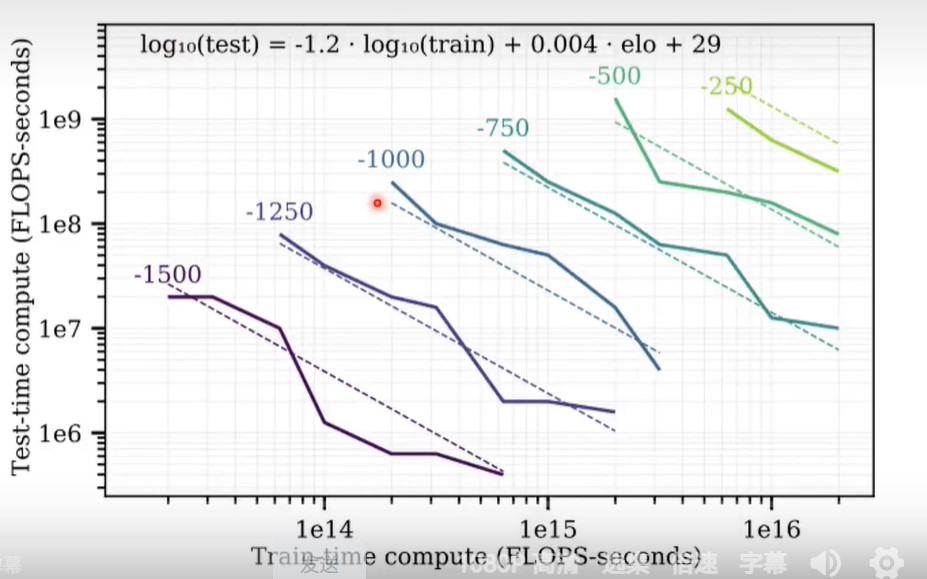
上图就表明,在test时投入更多的算力,和在train时投入更多的算力,二者的效果可以一样好。

- COT
分为few-shot cot和zero shot cot。

- 给模型推理流程
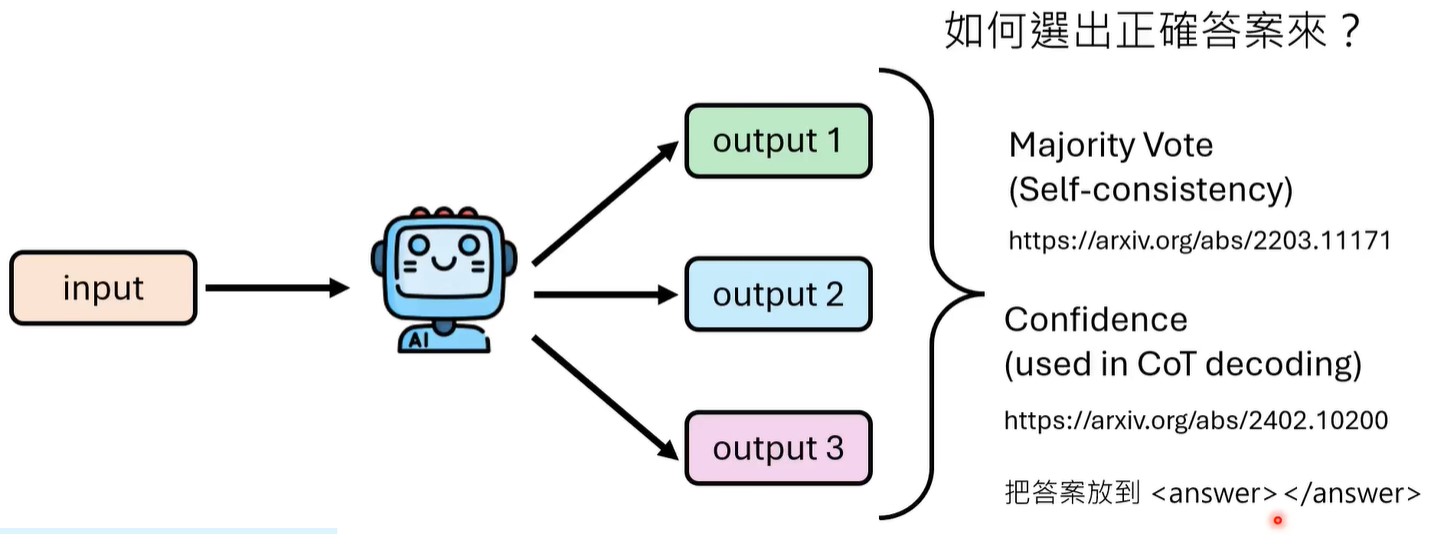
实际就是非greedy decoding,进行多次采样,选择出现频率最高的answer,或用选择答案confidence最高的。
关于如何确定response中哪些token是答案呢?在prompt中显式指定答案包裹在<answer></answer>中。
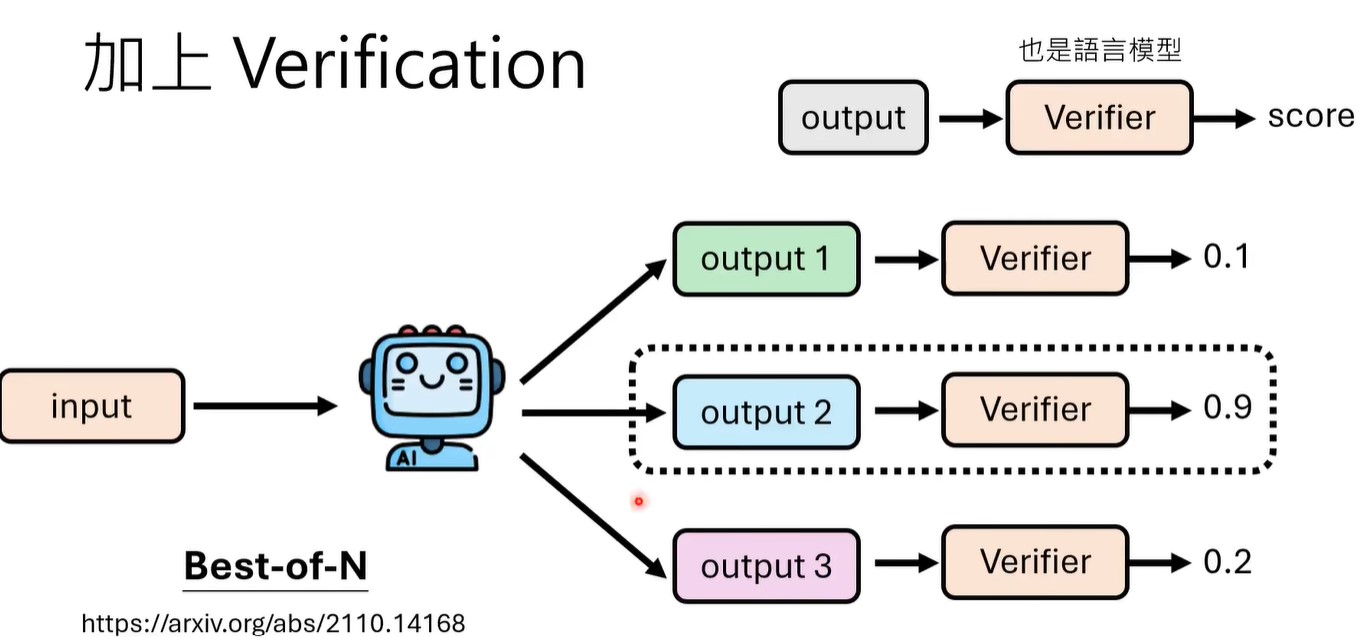
除了majority vote之外,还可以对多个output进行验证,即用一个verifier得到output的分数,选择最高得分的那个output。verifier可以通过训练得到。
如果对整个output进行verification的话,那么output可能是一大段错误的推理后输出的错误答案,此时虽然经过验证之后知道是错误答案,但白白浪费生成了大量token,所以可以对中间step就进行验证。
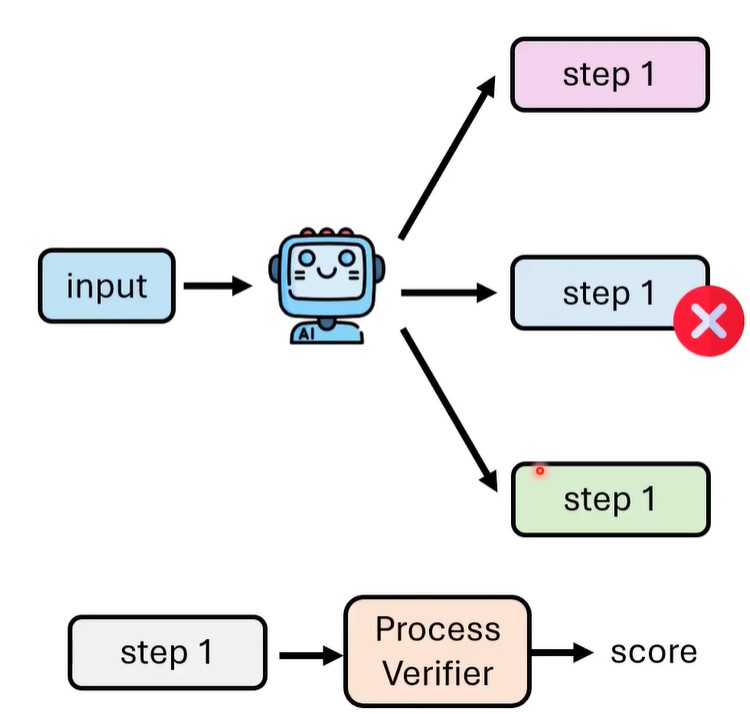
那么每个step的score如何得到呢,可以进行多次采样,假设所有包含step1的路径有n条,其中m条路径得到了正确答案,那么step1的score就是m/n。就可以用这个score作为ground truth,训练process verifier。
process verifier输出的是score, 也就是0-1的值,那么可以每个步骤选择最高score的step,也可以采用束搜索,每步保留n步最高score的路径。
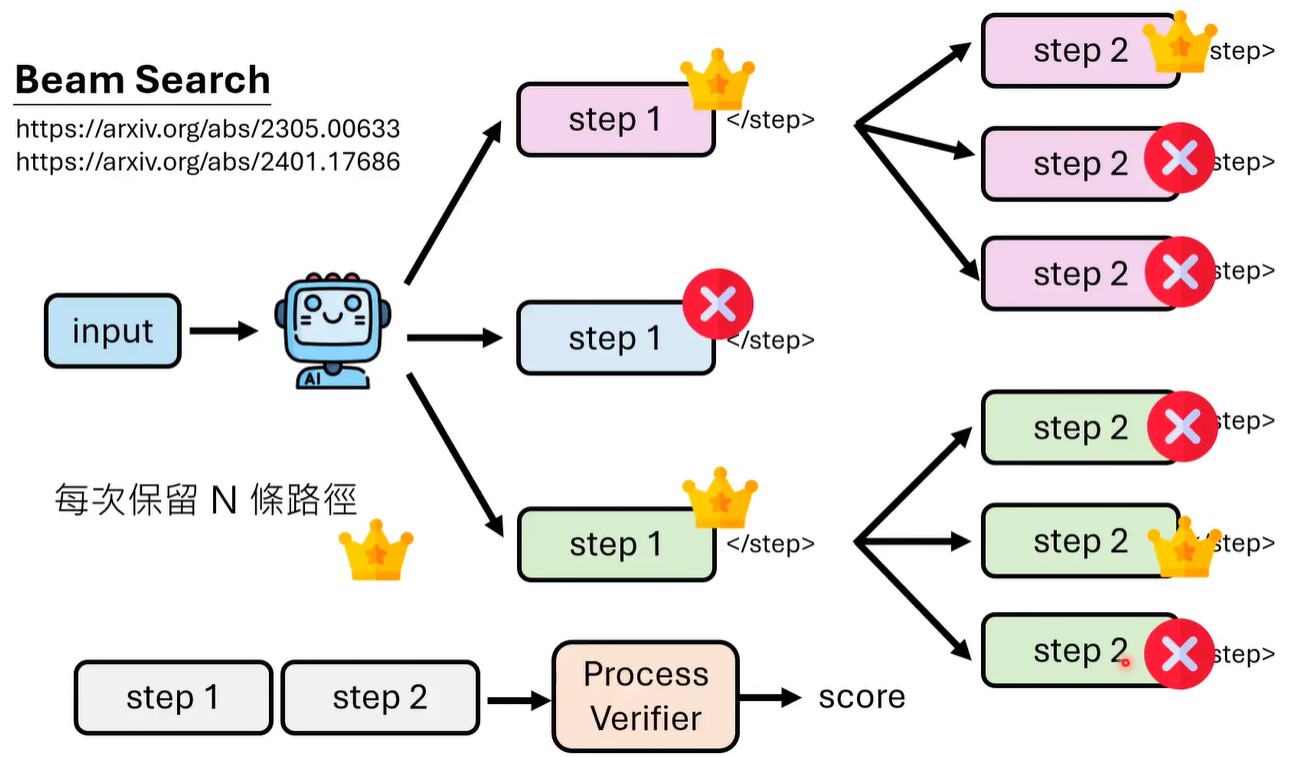
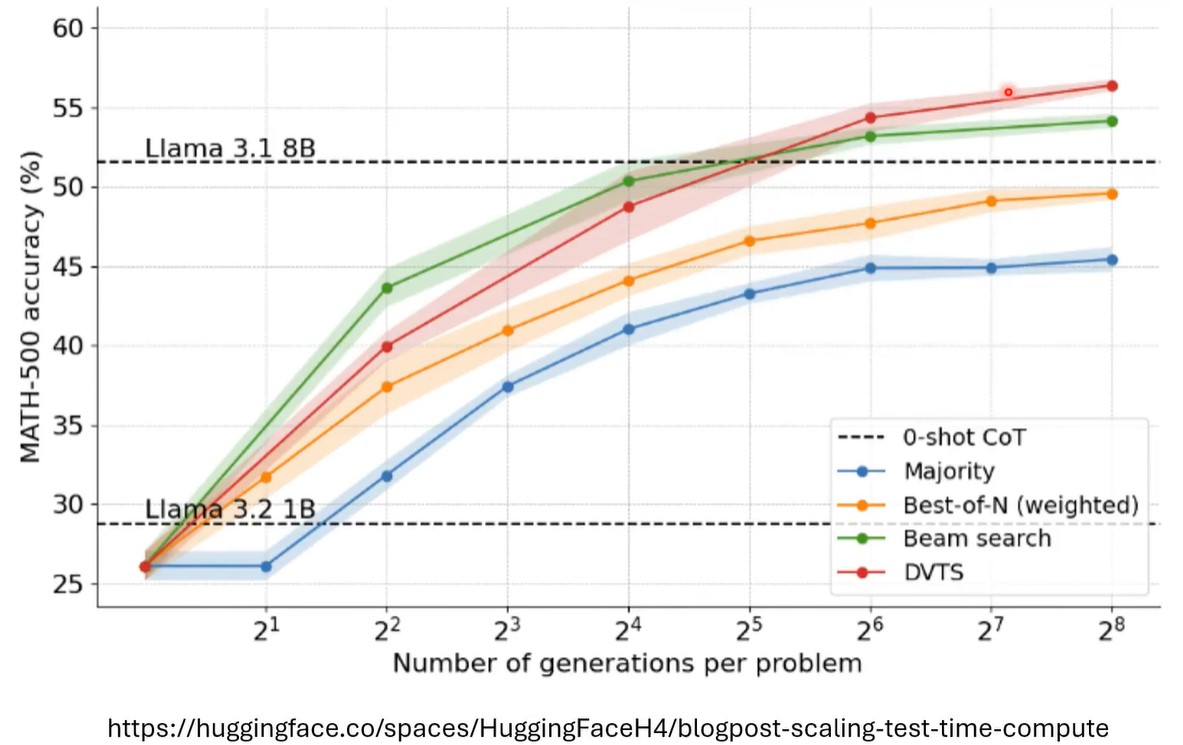
可以看到,beam search这种方法,可以让llama 1B模型达到llama 8B模型的准确率。
beam search有很多变体,如morto carlo tree search等,可以用在这里。
- 教模型推理流程
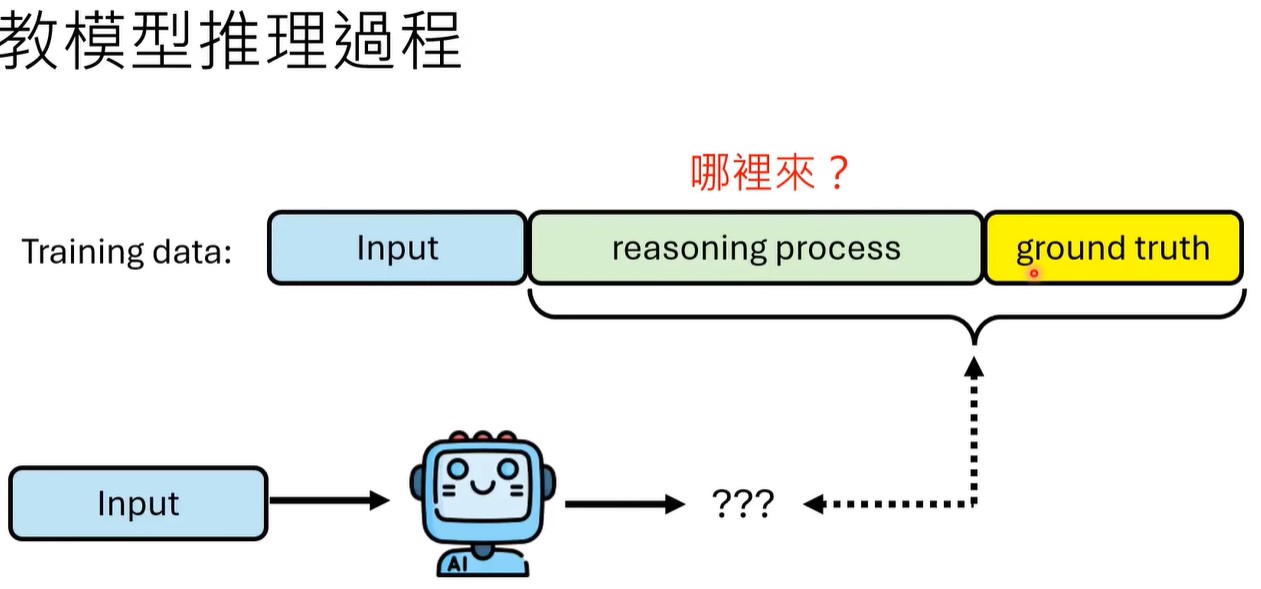
也就是SFT。
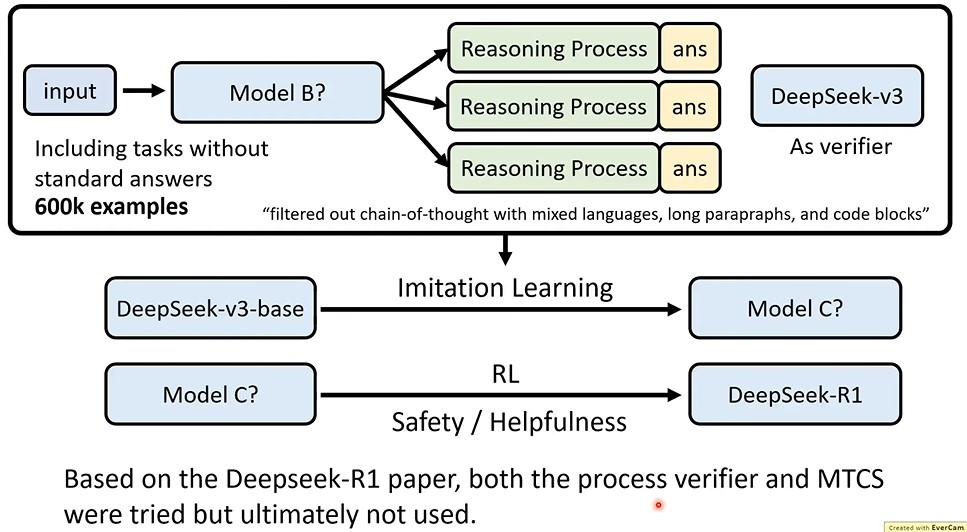
reasoning process可以来源于人类标注,也可以是llm生成的。
对于llm生成的reasoning process,最简单的做法是只挑选answer正确的那些reasoning response,也就是下图中左面的shortcut learning,但是这样就相当于只教模型正确的做法,模型只会打顺风局,不会打逆风局。还应该教给模型改正错误的能力,即journey learning。
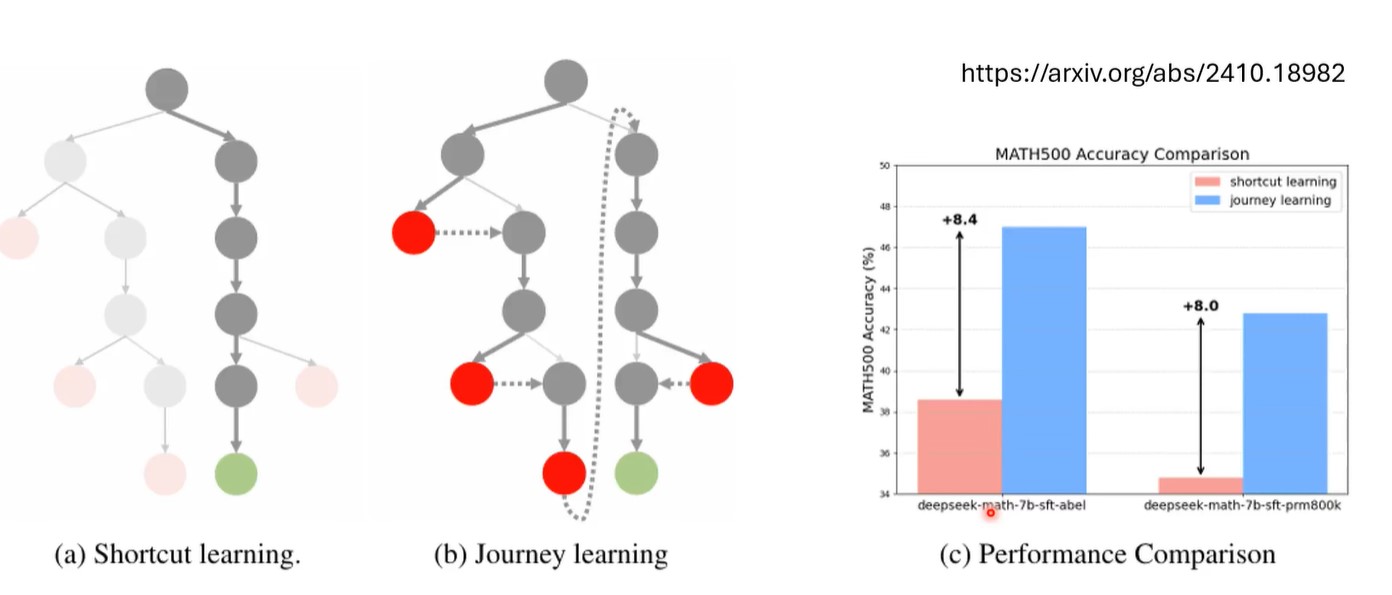
现在,一种获得reasoning process训练数据的简单方法就是knowledge distillation,用reasoning Model的 reasoning process数据来训练学生模型。
- RL,只以结果为导向
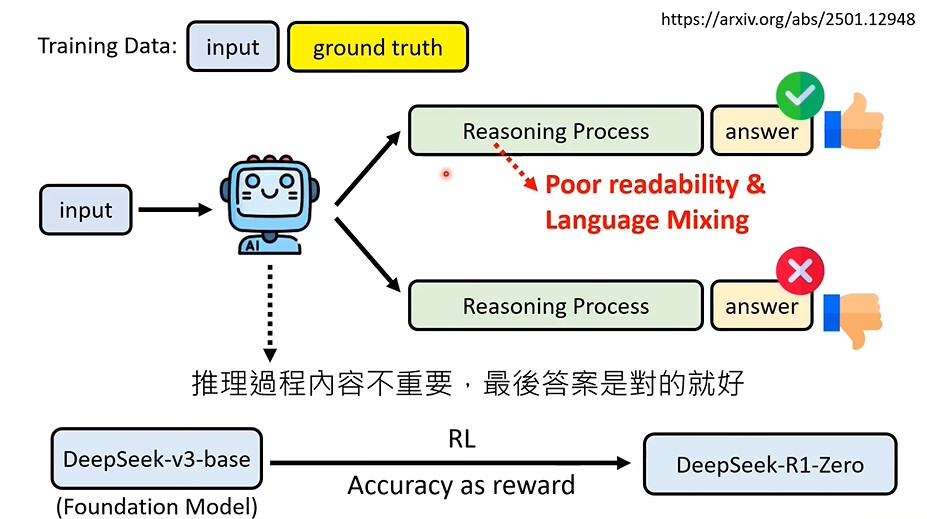
Deepseek-r1-zero是纯用强化学习训练的,它的reasoing process会出现Aha moment,但是这个reasoning process的可读性很差,且多个语言混杂,并不用供用户真正使用。
真正能使用的 Deepseek-r1-zero是如何打造出来的呢?
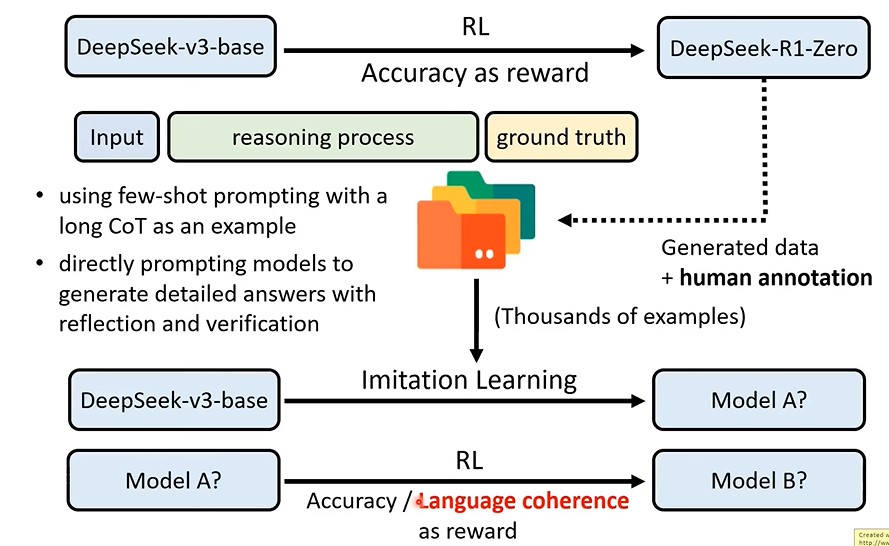
一个是对可读性差的reasoning process进行人工标注,然后再训练。另一个在RL reward中加入language coherence。
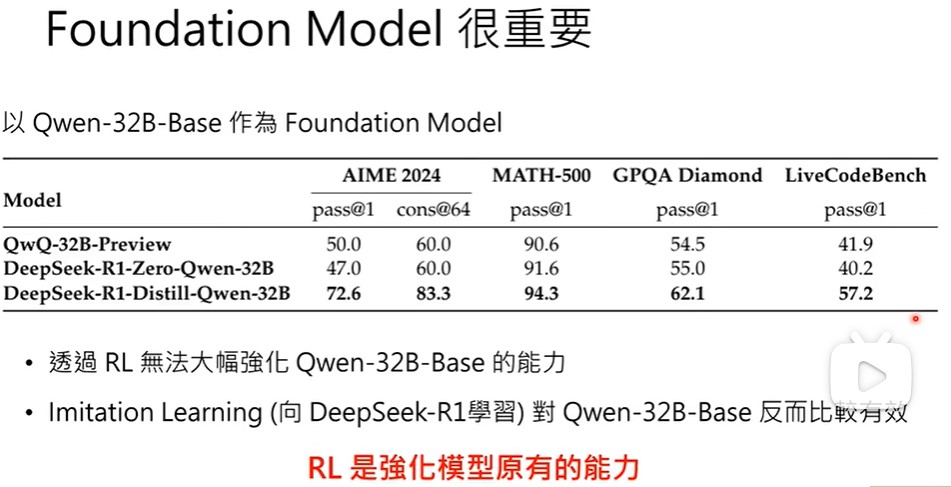
强化学习,foundation model很重要,对qwen32B做rl,就没什么效果。RL是强化模型原有的能力,模型本身就有回答正确的能力,RL只是强化这一路径,如果模型本身就没有能力,RL很难通过尝试不同路径找出正确路径并强化它。

Deepseek-v3本来就会Aha!
第8讲-别让推理模型想太多
推理长度和回答正确率之间有关系吗,是不是推理越长,回答准确率越高呢?
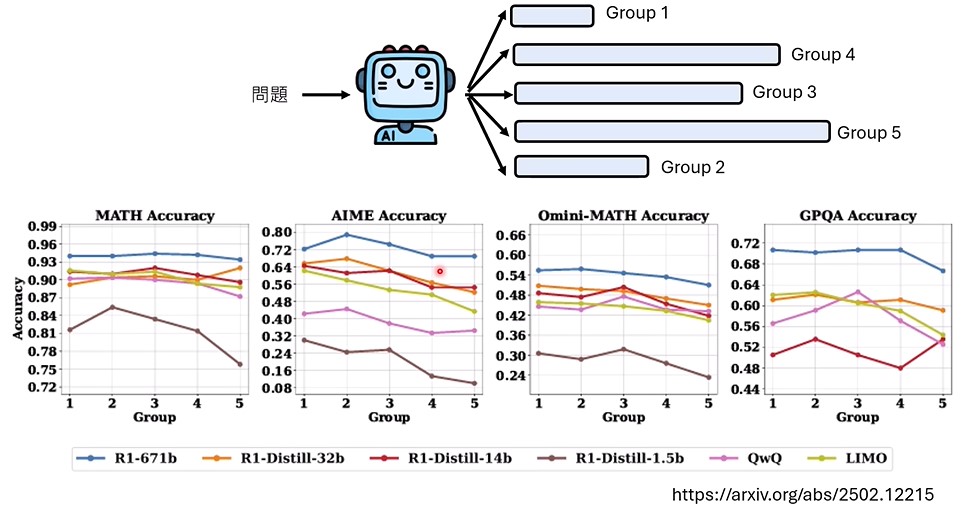
可以看出,推理越长,准确率反而越低(其实跟任务有关,有的任务推理越长,准确率越高)。推理越长,浪费的计算越多。
如何让模型不要想太多?还是从4个方面。
1.直接在cot prompt中限制

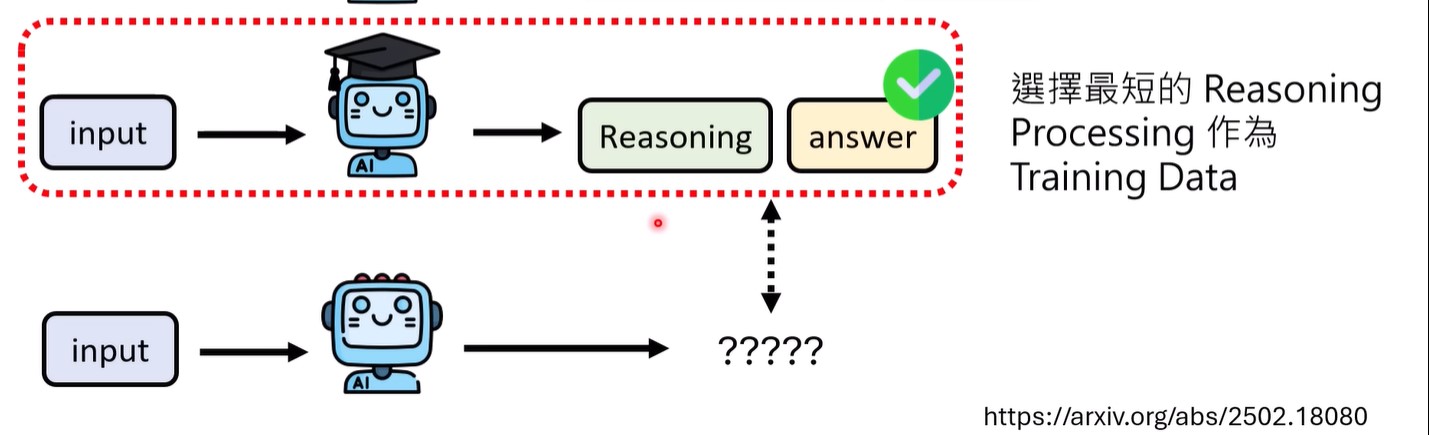
3.SFT用短的reasoing数据训练
4.RL
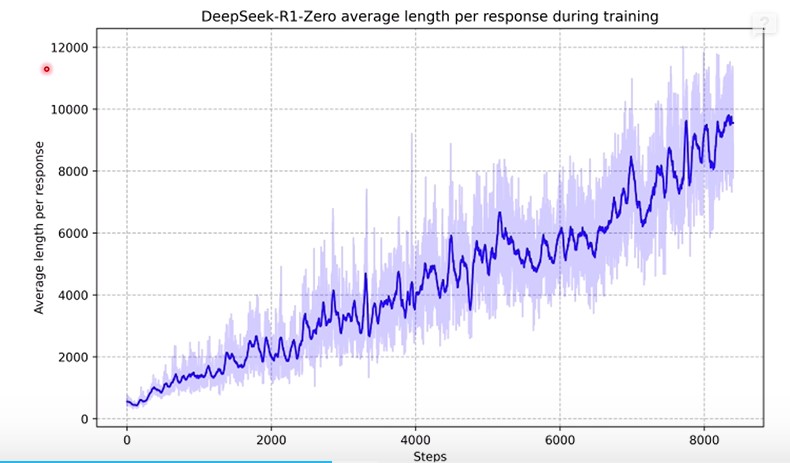
在Deepseek r1中,随着训练进行,推理长度越来越长。
在reward中加入对推理长度的限制 ,如果 推理长度大于正确回答该问题所需要的平均长度,就惩罚。