CS336-2025-lec1
2025年6月25日
10:22
Overview, tokenization
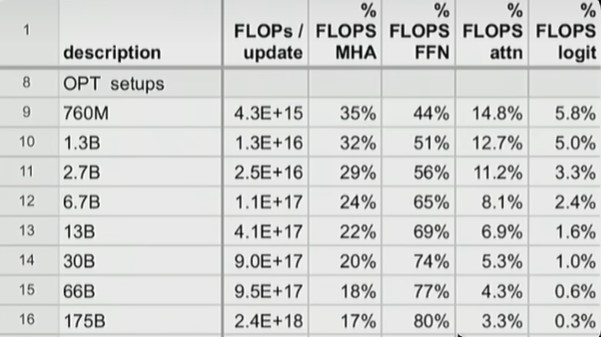
当参数量较小时,MLP和MHA的FLOPS计算量大致相当,但是当参数量很大时,MLP的FLOPS占主导地位。所以优化ATTENTION运算对于大模型的好处要小于小模型。
大模型训练时具有涌现现象,在训练到某个FLOPs数量以前,指标一直很低,但是到了某一步之后,指标突然增加。
优化大模型的计算效率很重要,因为资源是有限的,有限的GPU,有限的显存,有限的数据,有限的时间等。
A rule of thumb: 训练所需要的token数量大致是模型参数量的20倍,即1B的模型需要在20B的tokens上训练。
对齐Alignment:
base model is good at completing next token, Alignment makes the model actual useful.
对齐的目标:
1. Get the language model to follow instructions.
2. Tune the style, format, tone, etc.
3. Safety, refuse harmful questions
对齐的两个阶段:
1.SFT,微调模型使得p(response|prompt) 概率最大化,基本和预训练一样。
2.learning from feedback
1)偏好数据, A和B哪个好
2) verifiers , 如llm as judge
3)算法:PPO DPO(仅适用于偏好数据) GRPO
Byte Pair Encoding (BPE)
Basic idea: train the tokenizer on raw text to automatically determine the vocabulary.
Intuition: common sequences of characters are represented by a single token, rare sequences are represented by many tokens.
The GPT-2 paper used word-based tokenization(pre tokenization) to break up the text into inital segments and run the original BPE algorithm on each segment.
Sketch: start with each byte as a token, and successively merge the most common pair of adjacent tokens.