CS336-2025-lec5
2025年10月22日
9:56
GPU
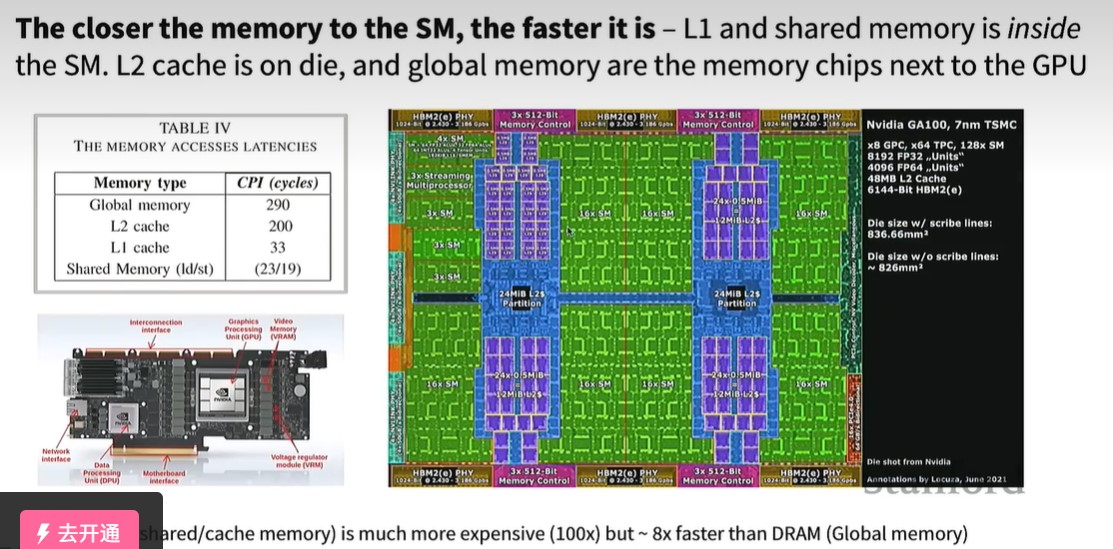
GPU有很多的SM组成,SM是stream multiprocesser,即上图中的绿色区域。每个SM有多个SP,single processer.
memory越靠近SM,传输速度越快,L1和shared memory在SM内部,而L2 cache在SM旁边 ,即上图中的蓝色区域。而Global memory在GPU的旁边 ,上图中实物图GPU的左右两列小方块就是VRAM,vedio memory,也就是显存 。显存和GPU的传输通过HBM,即上图中的最上面的黄色小方块。计算速度的进步要快于显存传输速度的进步,显存传输成为GPU运算速度的主要瓶颈。
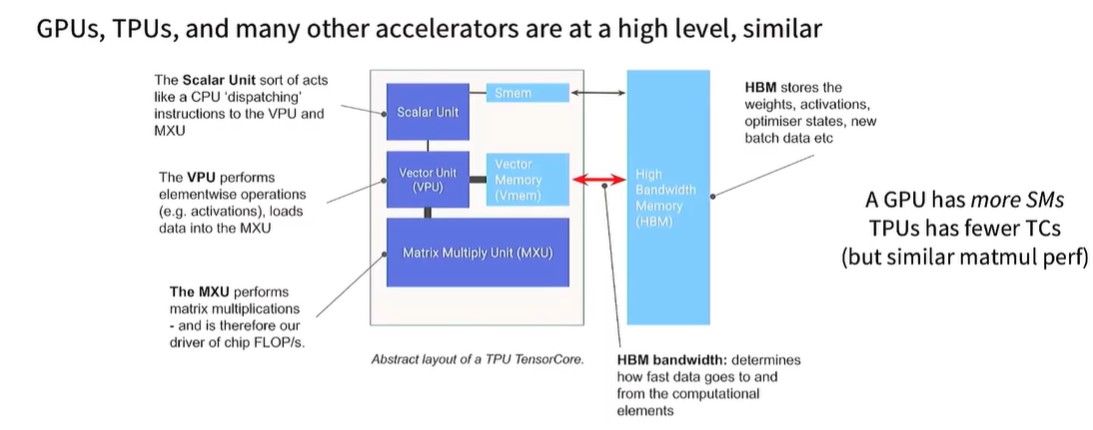
TPU的架构和GPU有相似之处,内部有专门处理向量和矩阵的单元,VPU和MPU
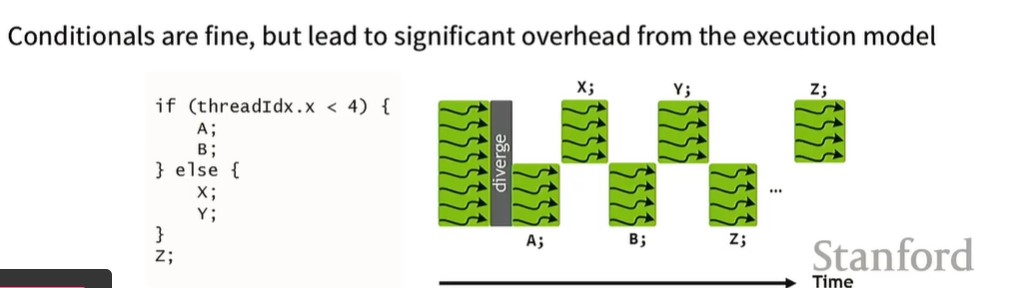
GPU是SIMT架构,Single instruction multiple thread,也就是线程束warp中多个thread执行同一个指令,因此,下图中的指令效率是很低的,
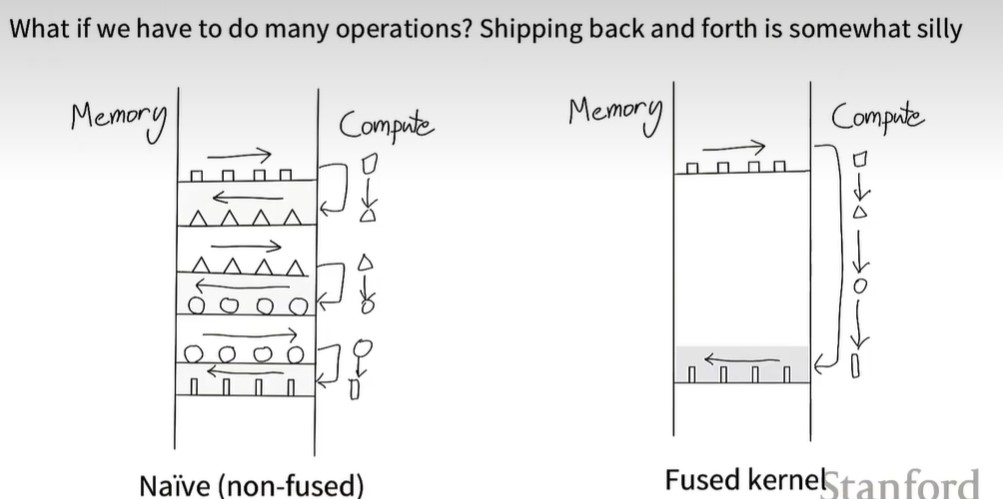
GPU加速Trick: 总之一个原则 ,减少和global memory的通信。
- 降低精度
- Kernel fusion,即torch.compile,一口气计算完成后再传输到global memory中
- Recomputation,也就是梯度检查点,不存储激活值,因为前向传播需要存储到显存,反向传播时需要读取显存,而memory access的速度慢,还不如再重新计算。同时,也可以节省显存,防止OOM。
- Memory coalescing,一次性读取多个字节,而不是一个一个取。类似,一次性把话说完,别一会说一句,过一会又说一句。
- Tiling,分块。对于矩阵相乘,原始做法是每个thread独立地按行或按列取数,这样每个数被重复读取了多次,如下图,M0,0被thread0,0和thread0,1取了两次,
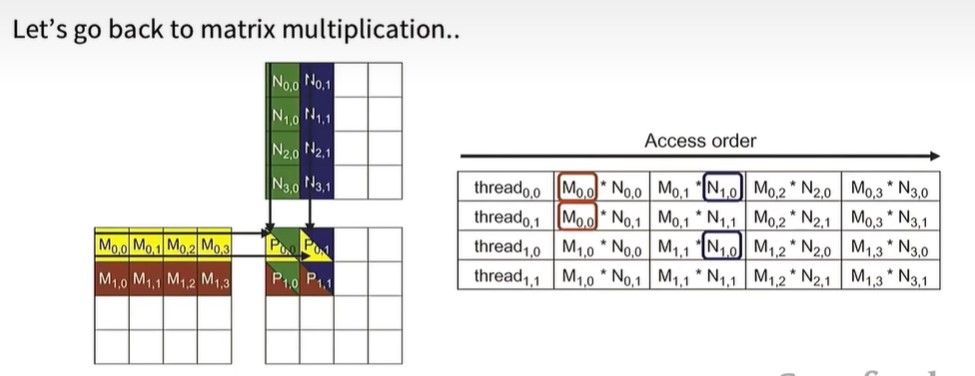
分块后,一次性取一小块,即M0,0 M0,1 M1,0 M1,1这一小块和N0,0 N0,1 N1,0 N1,1这一小块进行相乘,
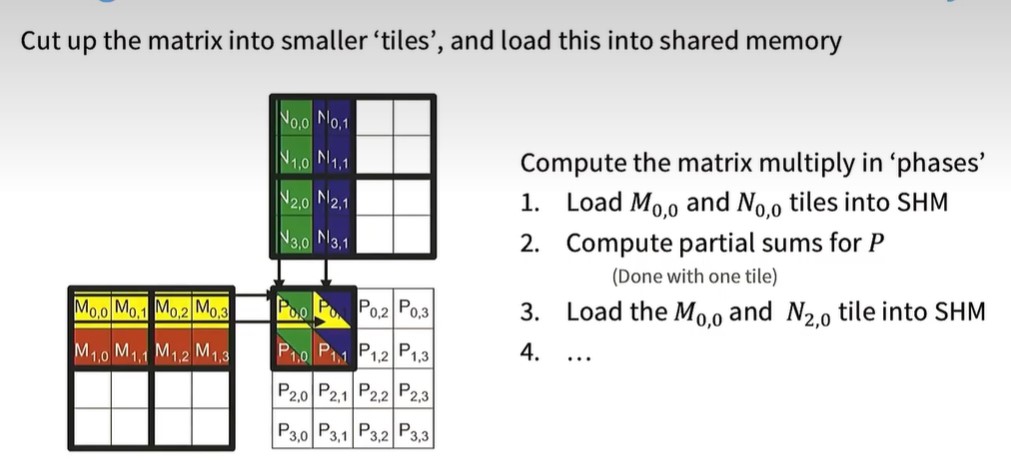
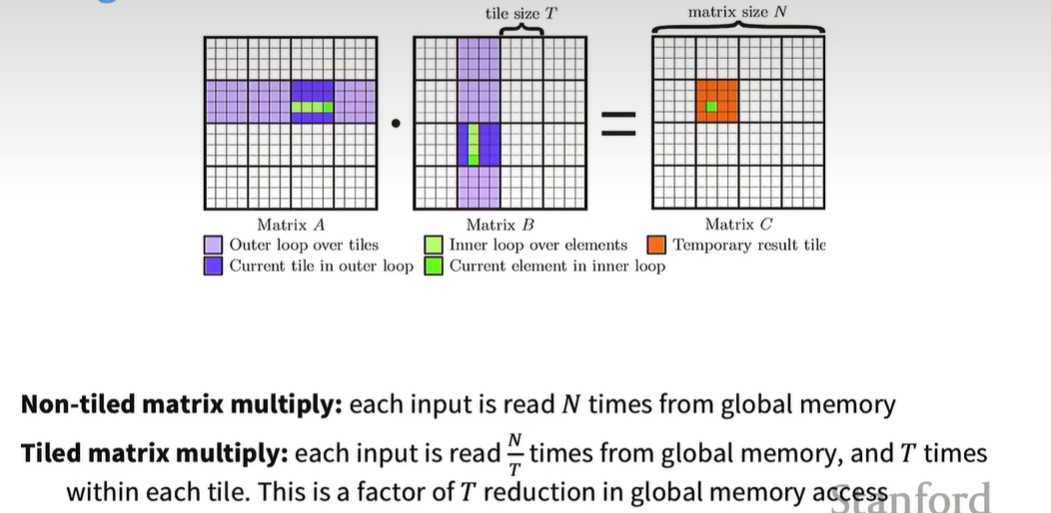
假设两个N*N矩阵相乘,原始做法,每个矩阵中的元素,从global memory中读取N次,而分块后,需要从global memory中读取N/T次,再从shared memory,即tile内部读取T次。
Flash Attention
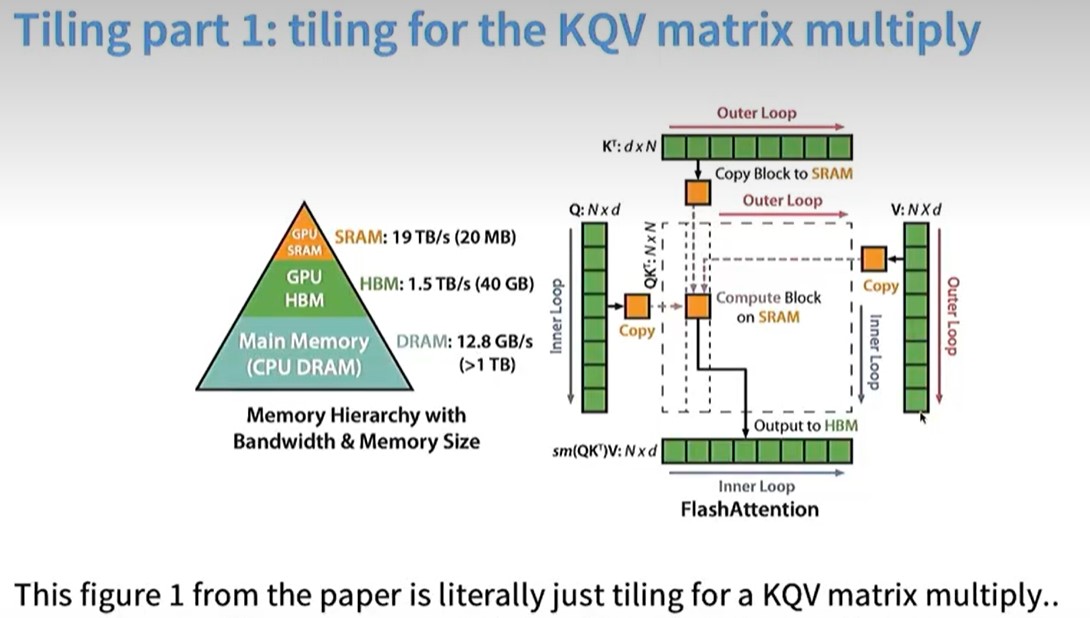
第一部分是对Q,K,V进行分块
第二部分是在线softmax,原始的softmax需要所有tile计算完后,才能得到每个tile的softmax值,在线softmax不需要。