CS336-2025-lec9
2025年10月28日
16:19
Scaling laws
大模型的训练成本是很高的,直接在big models tune hyperparameters这种方式不可行。
新的方法是tune on small models, extrapolate to large ones
也就是通过实验,得到模型效果和数据量、模型 超参数等的关系,这个关系就是scaling laws,然后就可以根据这个scaling laws直接选择最优的。
1.数据的影响
即Data scaling laws: simple formula that maps datasize to error.
数据肯定是越多越好。

从上图这两张scaling laws的实验可以看出,training data size越大,error越小。data越diverse,error越小。
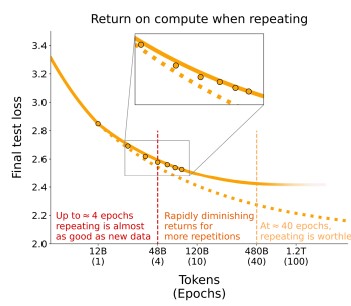
从上图这张scaling laws可以看出,当数据有限时,需要用重复数据训练模型,随着重复越来越多的数据,收益会迅速递减(后面的epoch中,loss下降的明显没有前面几个Epoch快)。
2.模型的影响
我们可以通过scaling laws来选择模型的超参数,
•Architecture,是用LSTMs vs Transformers哪种架构
•Optimizer,是用Adam vs SGD哪种优化器
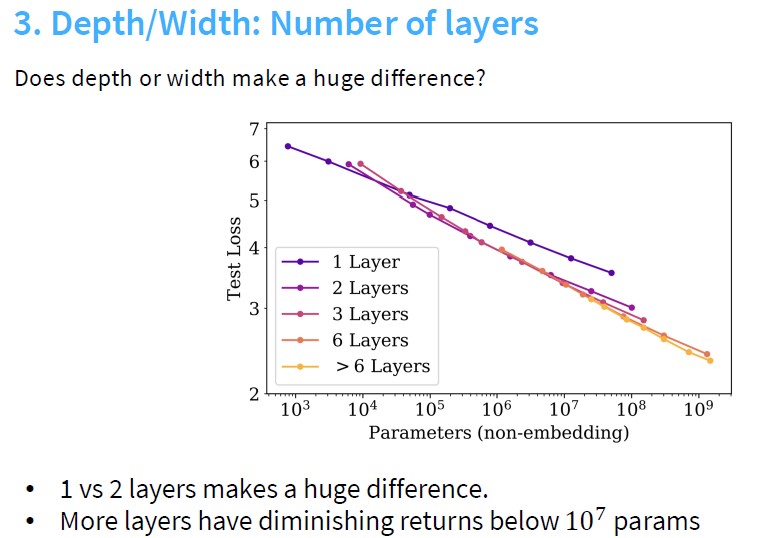
•Aspect ratio / depth
•Batch size
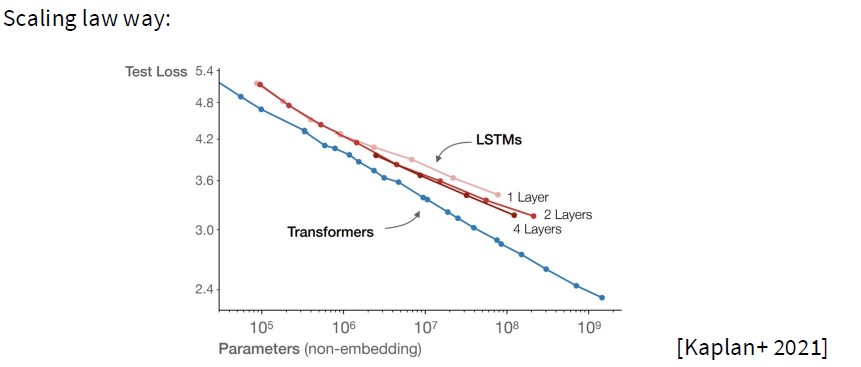
从上图可以看出,Transformer确实比LSTM好,全面胜出。也可以对比其他架构的模型。
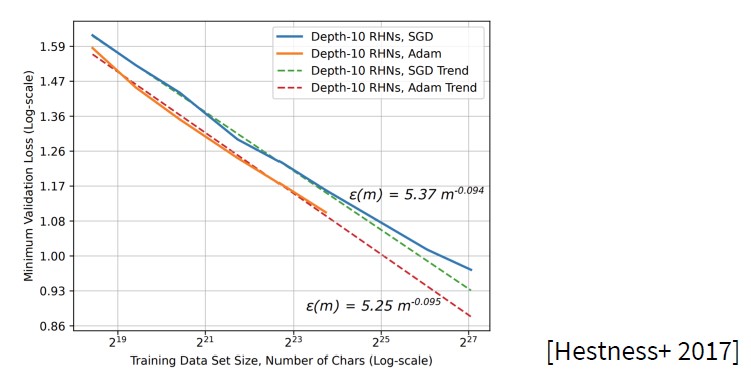
从上图可以看出,也是Adam好于SGD
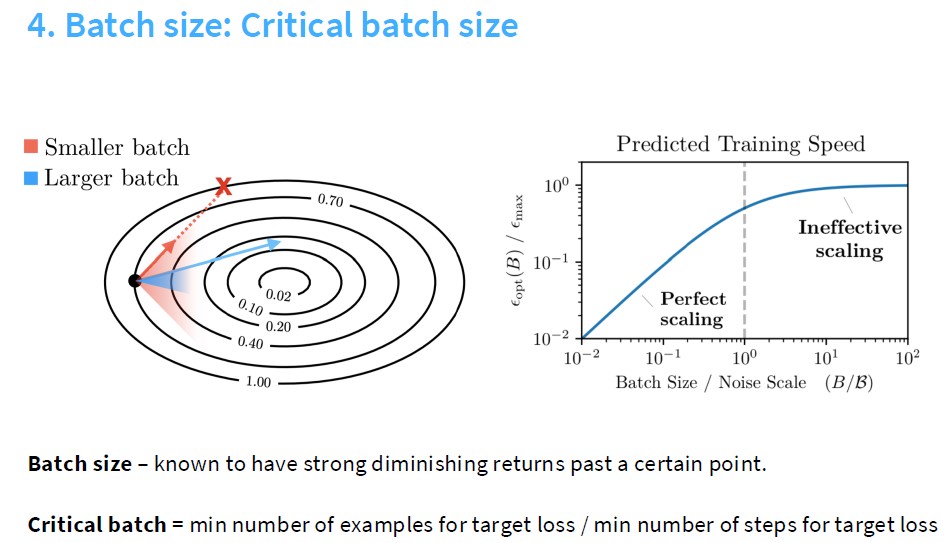
可以看到,关于batchsize的选择是有一个critical batch,在这之前,性能随着batchsize线性增加,在这之后,性能不变甚至下降,即batchsize过大,噪声会过大(极端情况下,只用一个batch训练的话,噪声比多batch要大)。
需要注意的是,scaling laws的纵轴可以是loss,也可以是下游任务的指标,如准确率等。那么纵轴从loss换为下游任务的评估指标时,scaling laws可能是不同的。
关于token数量和模型大小之间的scaling laws,大约是每个参数20个token来进行训练。但是我们一般是进行overtrain,因为对于LLM来说,主要是用它来进行推理,因此,我们用多于每个参数20个token的配置来训练,这样虽然用更多的token训练的增益增加得不如之前快,但还是有增益的,值得我们去进行训练。
But most of the compute in a real deployment is inference.. So we should ‘over’ train
•GPT3 – 2 tokens / param
•Chinchilla – 20 tokens / param
•LLaMA65B – 22 tokens / param
•Llama 2 70B – 29 tokens / param
•Mistral 7B – 110 tokens / param
•Llama 3 70B – 215 tokens / param
The more usage we expect, the more it becomes worth it to pay the upfront cost