MLA
2025
年
7
月
26
日
16:17
已使用 OneNote 创建。
![参考:
苏剑林. (May. 13, 2024). 《缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA 》[Blog post].
1.MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,
未命名图片.jpg 计算机生成了可选文字:
Ot
Ot
ton,<“鬱0
eIRdk
eIRdk
Wq
W
=CiVV
=CiVV
eRdxdk
eRdxdk
eRdxd
其中,𝒐𝑡表示第t个token的attention之后的embedding,𝒐𝑡(𝑠)表示第t个token在第s个attention head的embedding。
简单起见,这里省略了Attention矩阵的缩放因子。实践上,常见的设置是dk=dv=d/h,对于LLAMA2-7b有d=4096,h=32,dk=dv=128,LLAMA2-70b则是d=8192,h=64,dk=dv=128
由于这里只考虑了主流的自回归LLM所用的Causal Attention,因此在token by token递归生成时,新预测出来的第t+1
个token,并不会影响到已经算好的k(s)≤t,v(s)≤t,因此这部分结果我们可以缓存下来供后续生成调用,避免不必要的重复计算,这就是所谓的KV Cache。而后面的MQA、GQA、MLA,都是围绕“如何减少KV Cache同时尽可能地保证效果”这个主题发展而来的产物。
为什么降低KV Cache的大小如此重要?
众所周知,一般情况下LLM的推理都是在GPU上进行,单张GPU的显存是有限的,一部分我们要用来存放模型的参数和前向计算的激活值,这部分依赖于模型的体量,选定模型后它就是个常数;另外一部分我们要用来存放模型的KV Cache,这部分不仅依赖于模型的体量,还依赖于模型的输入长度,也就是在推理过程中是动态增长的,当Context长度足够长时,它的大小就会占主导地位,可能超出一张卡甚至一台机(8张卡)的总显存量。
在GPU上部署模型的原则是:能一张卡部署的,就不要跨多张卡;能一台机部署的,就不要跨多台机。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”,由于“木桶效应”,模型部署时跨的设备越多,受设备间通信带宽的的“拖累”就越大,事实上即便是单卡H100内SRAM与HBM的带宽已经达到了3TB/s,但对于Short Context来说这个速度依然还是推理的瓶颈,更不用说更慢的卡间、机间通信了。
所以,减少KV Cache的目的就是要实现在更少的设备上推理更长的Context,或者在相同的Context长度下让推理的batch size更大,从而实现更快的推理速度或者更大的吞吐总量。当然,最终目的都是为了实现更低的推理成本。
2.MQA
MQA,即“Multi-Query Attention”,是减少KV Cache的一次非常朴素的尝试,首次提出自《Fast Transformer Decoding: One Write-Head is All You Need》,这已经是2019年的论文了,这也意味着早在LLM火热之前,减少KV Cache就已经是研究人员非常关注的一个课题了。
MQA的思路很简单,直接让所有Attention Head共享同一个K、V,用公式来说,就是取消MHA所有的k,v
的上标(s):
未命名图片.jpg 计算机生成了可选文字:
O
ot
Ot
ton,
=W
=W
,Ot
eIRdk
eRdk
Et<t。№(q
Wq
WV
eRdxdk
eIR×
eRdxd](MLA.files/image001.png)

![未命名图片.jpg 计算机生成了可选文字:
O
ot
Ot
ton,
=W
=W
,Ot
eIRdk
eRdk
Et<t。№(q
Wq
WV
eRdxdk
eIR×
eRdxd
使用MQA的模型包括PaLM、StarCoder、Gemini等。很明显,MQA直接将KV Cache减少到了原来的1/h
,这是非常可观的,单从节省显存角度看已经是天花板了。效果方面,目前看来大部分任务的损失都比较有限,且MQA的支持者相信这部分损失可以通过进一步训练来弥补回。此外,注意到MQA由于共享了K、V,将会导致Attention的参数量减少了将近一半,而为了模型总参数量的不变,通常会相应地增大FFN/GLU的规模,这也能弥补一部分效果损失。
3.GQA
然而,也有人担心MQA对KV Cache的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个MHA与MQA之间的过渡版本GQA(Grouped-Query Attention)应运而生,出自论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》。
GQA的思想也很朴素,它就是将所有Head分为g个组(g可以整除h),每组共享同一对K、V,用数学公式表示为
未命名图片.jpg 计算机生成了可选文字:
Ot
<老
tonqt,
qt
([sg/hl)
k
([sg/hl)
Ot
([sg/hl)
<t
e]Rdk
(Isg/hl)T([sg/hl)
([sg/hl)T
'eR×
([sg/hl)eRdk厂
([sg/hl)
eIR×
([sg/hl)eRd",厂
([sg/hl)
eIR×
总结:MHA有n_head个𝑾𝒌和𝑾𝒗,MQA有1个𝑾𝒌和𝑾𝒗,GQA有n_group个𝑾𝒌和𝑾𝒗。](MLA.files/image003.png)





![未命名图片.jpg 计算机生成了可选文字:
Ot
Ot
ton,<“鬱0
eIRdk
eIRdk
Wq
W
=CiVV
=CiVV
eRdxdk
eRdxdk
eRdxd
在解码阶段的MLA则改为MQA形式,
未命名图片.jpg 计算机生成了可选文字:
0Wt,
0(2)只2)
E。。№@戾
E,。№@戾
eRdc+dr
[G,w,R]e
W(s)eR×W@)eR×以司eWe
c'=CiW'eRdc
XiVVeRdc
0
WceIR
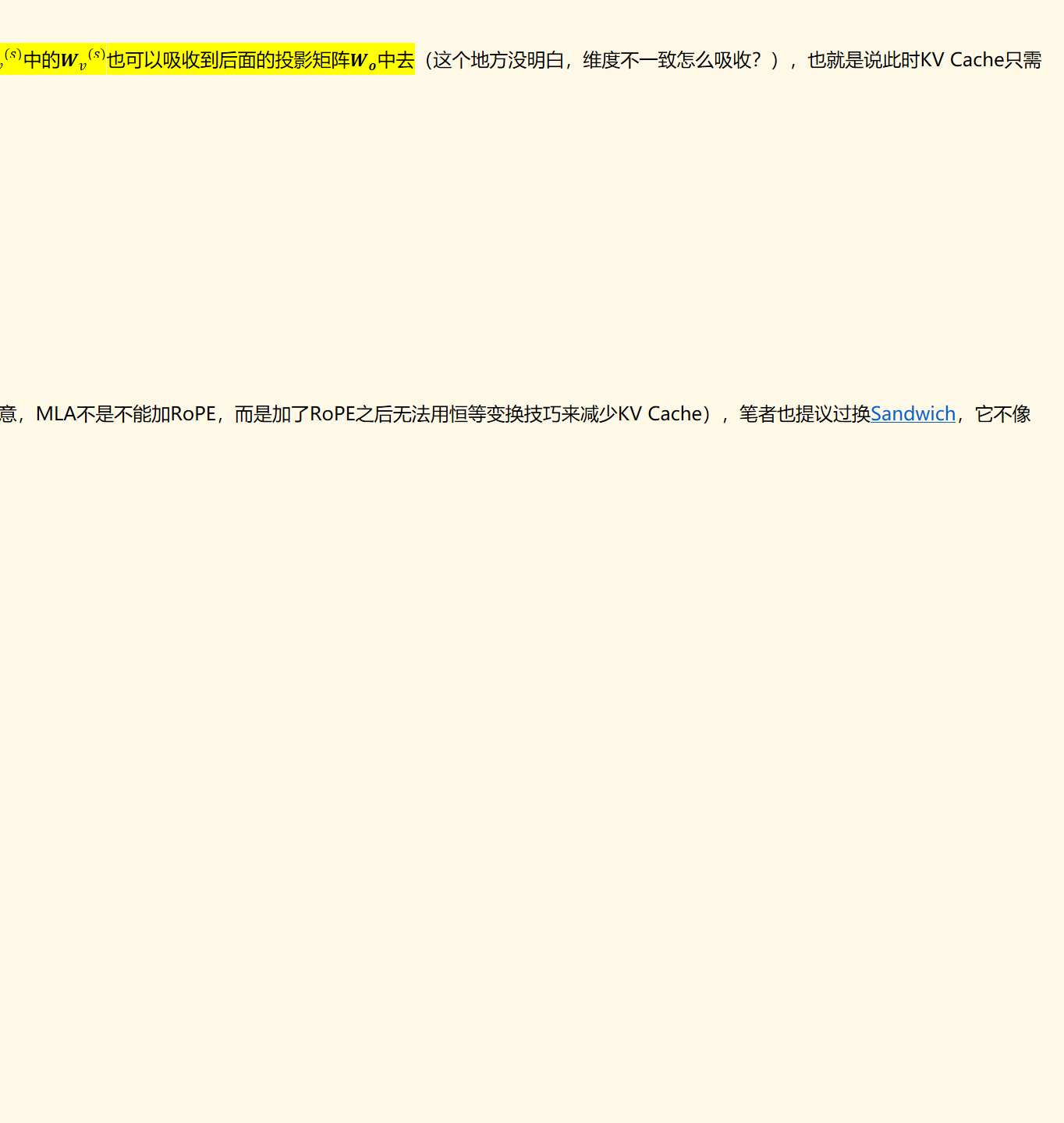
推理阶段与训练阶段的唯一区别在于,将𝒌𝒊(𝒔)的第一部分 𝒄𝒊𝑾𝒌𝒄(𝒔)中的𝑾𝒌𝒄(𝒔)挪到了𝒒𝒊(𝒔)的第一部分中,进行合并。由于𝒌𝒊(𝒔)的第二部分rope部分是多头共享的,所以𝒌𝒊(𝒔)整体变成了𝒌𝑖,变成了多头共享,即MQA的形式。
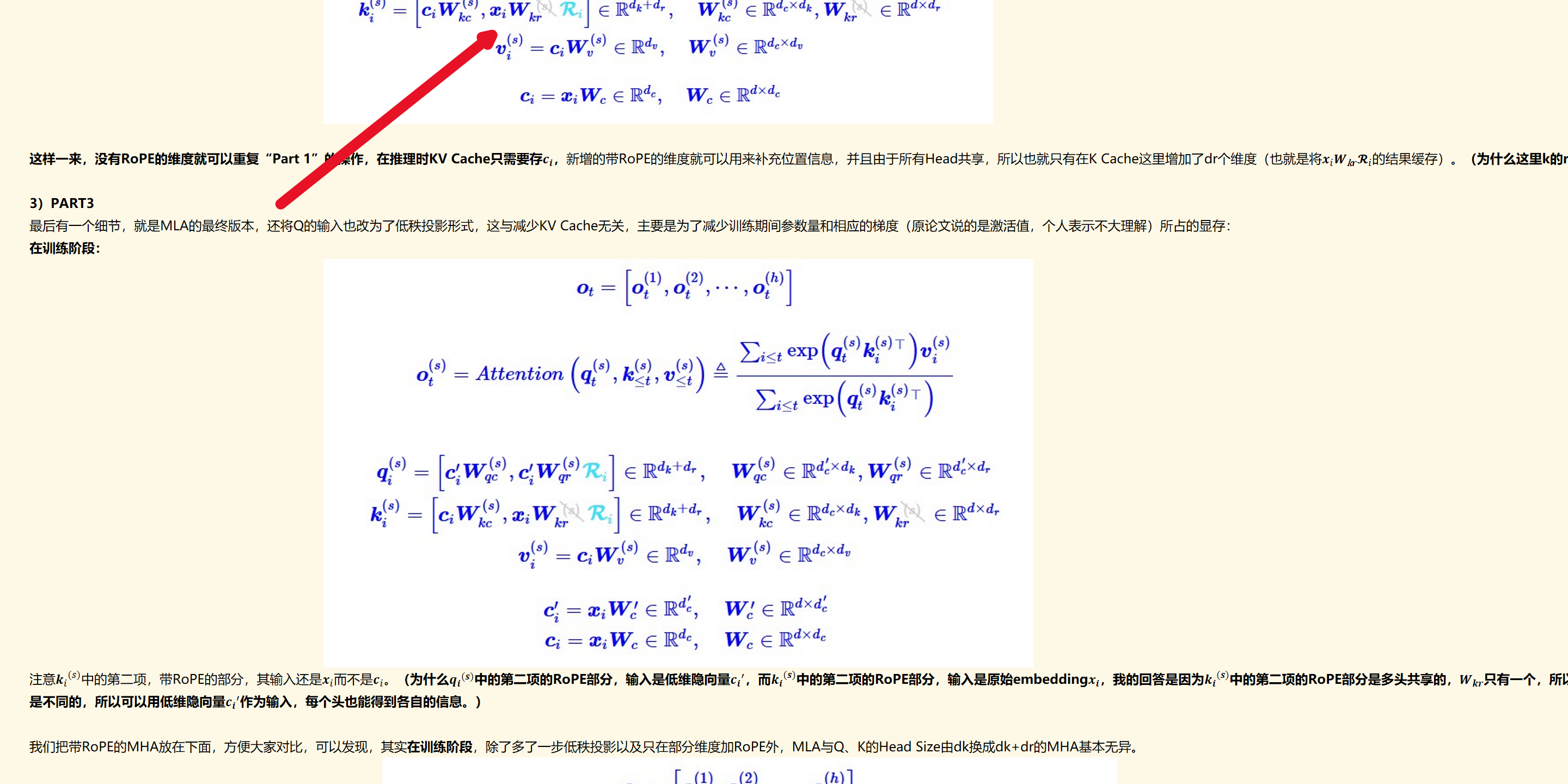
总结:MLA主要是将q和k分为了两部分,token embedding query/key和position embedding query/key,将rope部分单独拎了出来。将q的 第一部分 和k的 第一部分 进行点积,将q的 第二部分 和k的 第二部分 进行点积。k的 第一部分是MHA,在推理时,通过矩阵吸收,将这部分变成了多头共享,每个头都是𝒄𝑖 即MQA,第二部分rope本身就是MQA,所以在推理时,k整体变成了MQA。
所以在推理时MLA的缓存(训练时不需要缓存),只需要缓存𝒄𝒊 和长度为dr的rope向量(k的第二部分)。MLA的KV Cache大小跟h无关。
未命名图片.jpg 计算机生成了可选文字:
补充说明:
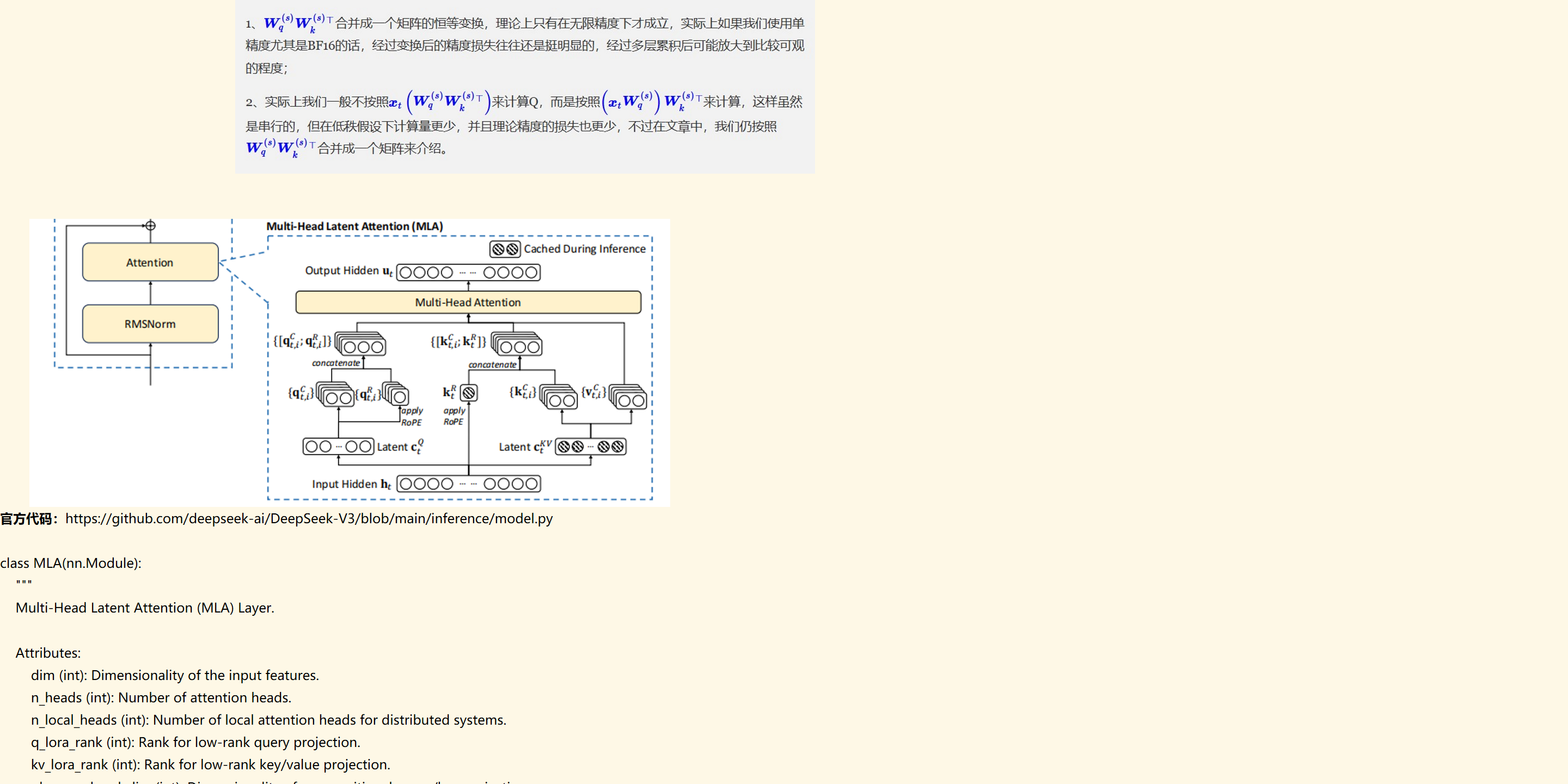
1w小)w小)T合并成一个矩阵的恒等变换,理论上只有在无限精度下才成立,实际上如果我们使用单
精度尤其是BF16的话,经过变换后的精度损失往往还是挺明显的,经过多层累积后可能放大到比较可观
2、实际上我们一般不按照Wq)w小)')来计算Q,而是按照ætWq)w小)'来计算,这样虽然
是串行的,但在亻失假设下计篡最更少,并且理论精度的损失也更少,不过在文章中,我们亻乃按照
小)W'固T合并成一个矩阵来介绍。](MLA.files/image011.png)



![self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False)
else:
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
Forward pass for the Multi-Head Latent Attention (MLA) Layer.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim).
start_pos (int): Starting position in the sequence for caching.
freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings.
mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns:
torch.Tensor: Output tensor with the same shape as the input.
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
if self.q_lora_rank == 0:
q = self.wq(x)
else:
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
if attn_impl == "naive":
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(self.kv_norm(kv))
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)](MLA.files/image016.png)
![k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
self.k_cache[:bsz, start_pos:end_pos] = k
self.v_cache[:bsz, start_pos:end_pos] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
else:
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
if attn_impl == "naive":
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return x](MLA.files/image017.png)
