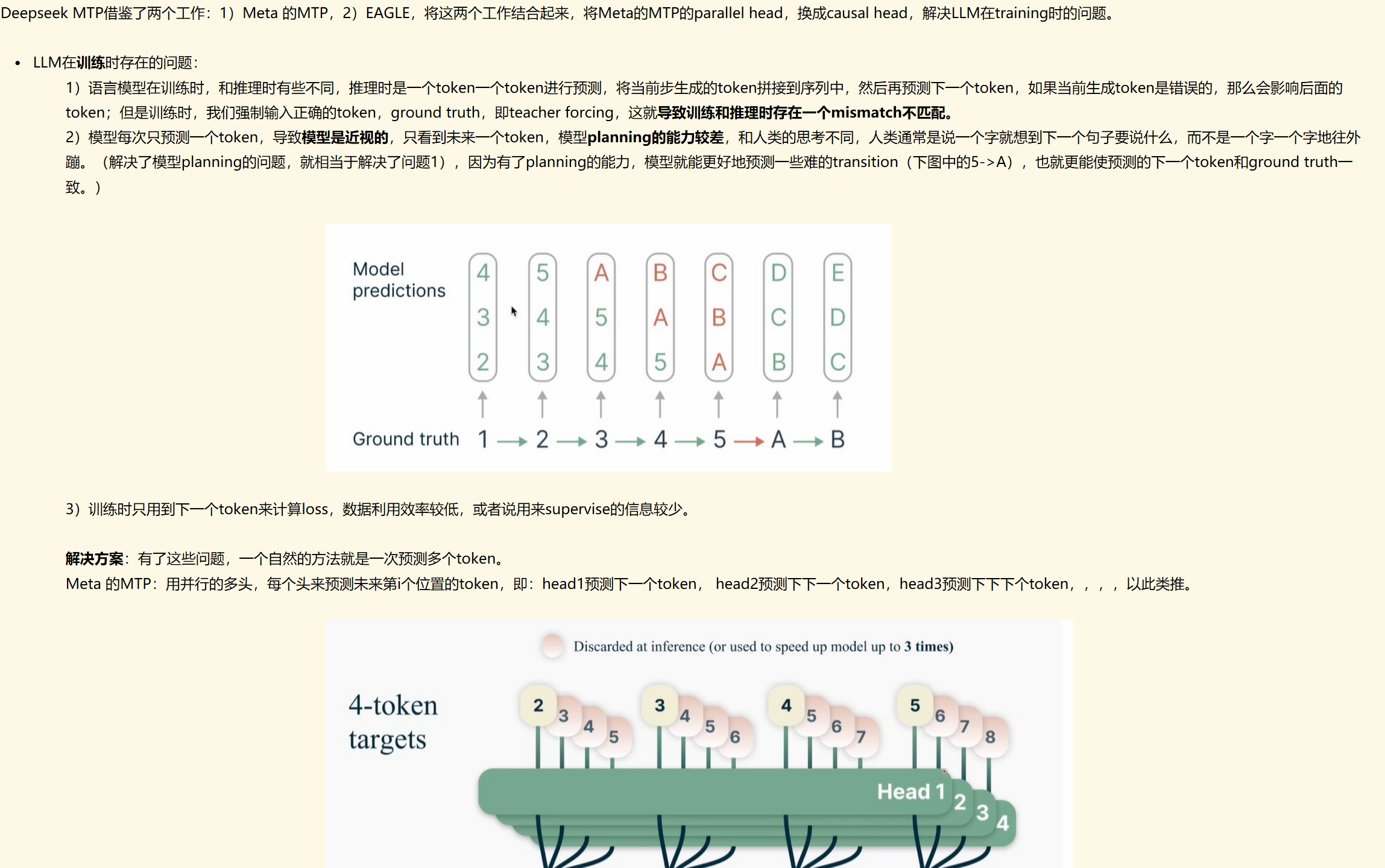
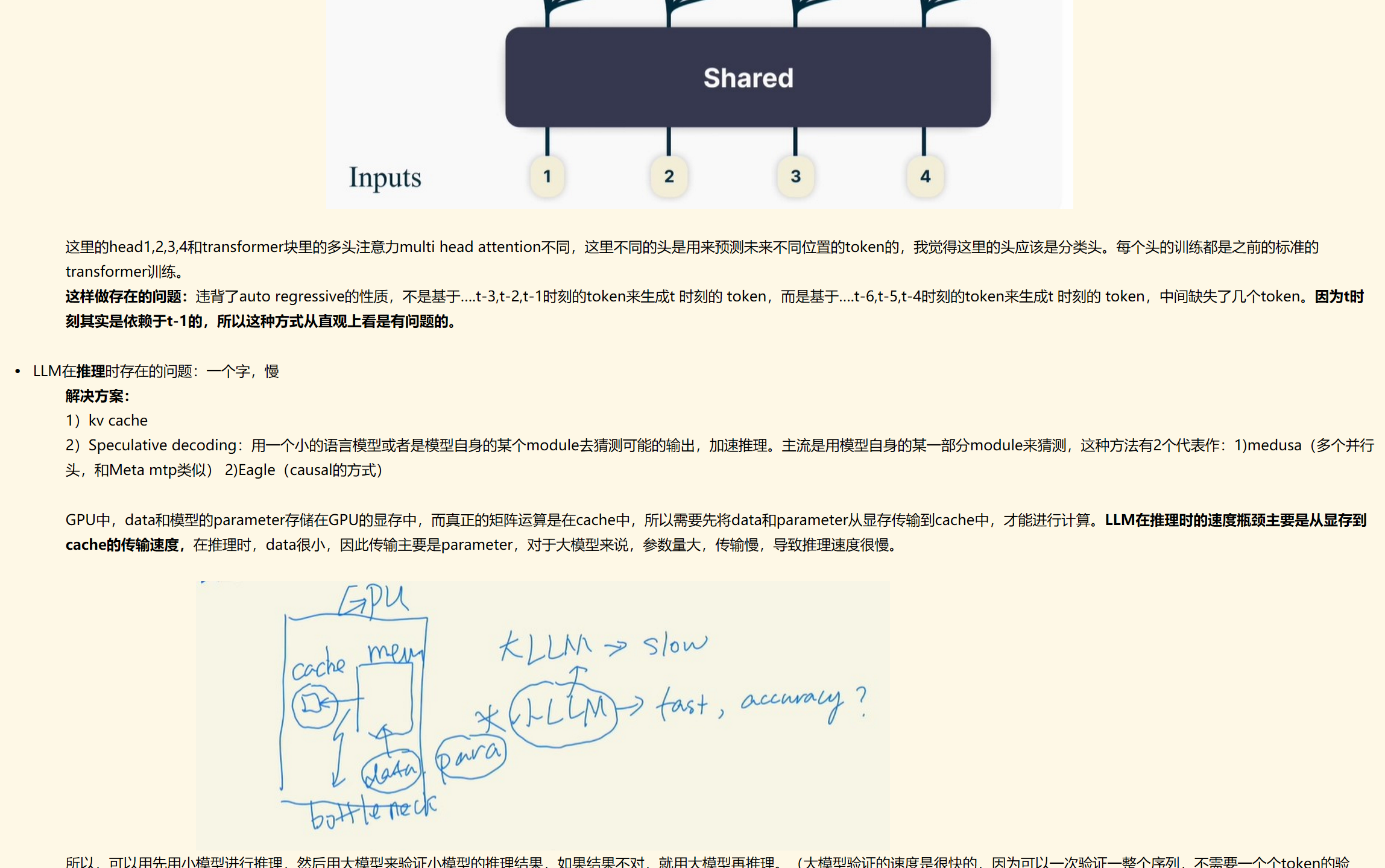
MTP
2025
年
9
月
6
日
15:50
已使用 OneNote 创建。
![所以,可以用先用小模型进行推理,然后用大模型来验证小模型的推理结果,如果结果不对,就用大模型再推理。(大模型验证的速度是很快的,因为可以一次验证一整个序列,不需要一个个token的验证,就不需要进行cache和显存之间的传输。)
speculative decode就是两个部分:1)小模型quick guess 2)大模型cheap verification。
未命名图片.jpg 计算机生成了可选文字:
[STARTI2
!STARTI
[STARTI
!STARTI
ISTARTI
sbenchmarkbondn
Sbenchmarknikkei22
Sbenchmarknikkei225indexrose2276
@sbenchmarknikkei225indexrose226
.sbenchmarknik1225indexrose226
Sbenchmarknikkei225indexrose226
Sbenchmarknikkei225indexrose226
sbenchmarknikkei225indexrose226
@sbenchmarknikkei225indexrose226
69points
,0re1
69points.
or1
69points
0r1
69points
0r1
69points
or1
,to10
,9859
》to10
989
989
,9的
,in
79intekyøtate
79intatemorningtrading
,(END]
绿色是小模型生成的,蓝色是大模型修正的。
用来guess的小模型可以是Independent的,也可以是大模型其中的一个module(更推荐,因为只一个模型,系统复杂度更低。),两个代表工作,medusa 和EAGLE,都是用在推理阶段的,具体原理没搞明白,反正就是medusa是并行头,EAGLE是casual的。causal要好于并行的,Deepseek就采用了causal。
未命名图片.jpg 计算机生成了可选文字:
TargetTokens
Cross-EntropyLOSS
MainModel
《(NextTokenPCt/0司
OutputHead
TransformerBlock×L
EmbeddingLayer
Input丆bke們
•CMain
Shared
Shared
Cross-EntropyLOSS
MTPModule1
(Next?Tokened化00n丿
OutputHead
TransformerBlock
LinearProjection
concatenation
RMSNormRMSNorm
EmbeddingLayer
Cross-EntropyLOSS
MTPModule2
《e冠3Token件ed忆on丿
0utputHead
TransformerBlock
LinearProjection
concatenation
RMSNormRMSNorm
EmbeddingLayer
MTP
Shared
Shared
墨迹绘图](MTP.files/image003.png)
