比赛总结
2025年5月28日
10:33
# Draw with llms
## Pipeline
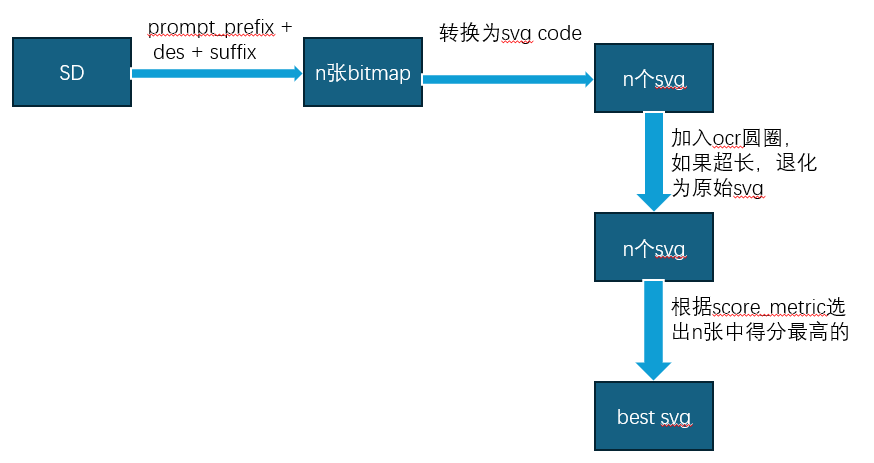
### SD的选择
sd2.0
sdxl-turbo
sdxl-lightning
enable_cpu_offload()之后,sd不占用gpu显存了?占用的是cuda:0的显存,最初是加载到cuda:1的,运行时变成加载到cuda:0上了
sdxl-lcmlora
flux.1-schnell✅
### SD prompt的选择
prompt_prefix
prompt_suffix
```
prompt = "Simple, minimalist drawing of gray wool coat with a faux fur collar with mosaic style, vector graphics, SVG-like, solid colors only"
```
prompt_prefix = "Extremely simple, ~~Close-up,~~ SVG-style image of" 加了close-up后, 图片确实近景了,但是看不出来是个什么东西,如裤子上的纽扣,只能看出纽扣,看不出裤子。✅
prompt_suffix = "with flat color blocks, beautiful, minimal details, solid colors only"
prompt = "Simple drawing of gray wool coat with a faux fur collar"
### bitmap转换为Svg代码
vtracer非常快
vtracer验证是是否只包含path标签,只包含translate平移操作✅
### ocr圆圈
加入圆圈后超过10000,变为default_svg✅
加入圆圈后不用再做Ocr检测了,节省时间✅。反正进行ocr检测前,也进行random transform,自己检测的也不100%准确 。是的,自己检测的不准确 ,因为如果改为本地ocr检测不为1时再加入圆圈,那么LB分数会下降很多,说明本地ocr检测的不准确,很多自己检测ocr分数为1的图片,官方实际的ocr分数不是1。但是赛后来看,还是加入ocr检测的得分更鲁棒。
### score_metric
what is the point of increasing the number of images if your score metric is bad?
仔细分析一下,4个多选问题和static question的差别。
**static question关注的全局,整体,而generated question关注是局部,是画面中是否明确包含description中的元素。**
**debug,把vqa_topic和vqa_element的得分打出来,看一下。**
~~static question更倾向于选细节更多的,也就是svg长度更长的??~~应该不是这个原因。
siglip得分选第二高的和第一高的,PLB的得分都是0.645,说明跟比赛的metric有出入 。
siglip + ace_score ,beta=0.5相当于siglip_weight=0.8
siglip权重变小 + ace_score ,beta=0.655相当于siglip_weight=0.7
beta=0.57735相当于siglip_weight=0.75
(vqa单个问题+siglip平均) + ace_score ,beta=0.5
version27 + siglip score PLB 0.621==>0.612,所以siglip metric不如原来的vqa_evaluator✅
通过构建vqa_regressor数据集,建立ridge模型预测,打印特征重要性,发现topic和siglip_prefix_score对vqa_score的预测最重要。而且与public LB的得分也一致。最后选择二者的调和平均。✅
一些trick:
1.将生成的图片(预测的结果)打印出来,debug,才能发现问题,如图片Ocr得分是0,bitmap--->svg转换地不清晰等问题。