强化学习的数学原理-第10课
2026年1月11日
16:13
Actor-Critic
off policy actor-cirtic
通过importance sampling将On policy转为off policy
前面介绍 的Policy gradient算法是on policy的,因为梯度是个期望的形式,通过采样得到梯度,同时
进行对策略参数进行更新,更新的policy和采样的policy是一样的。

重要性采样的出发点是,从服从p1分布的x中的采样,来估计服从p0分布的x的期望。
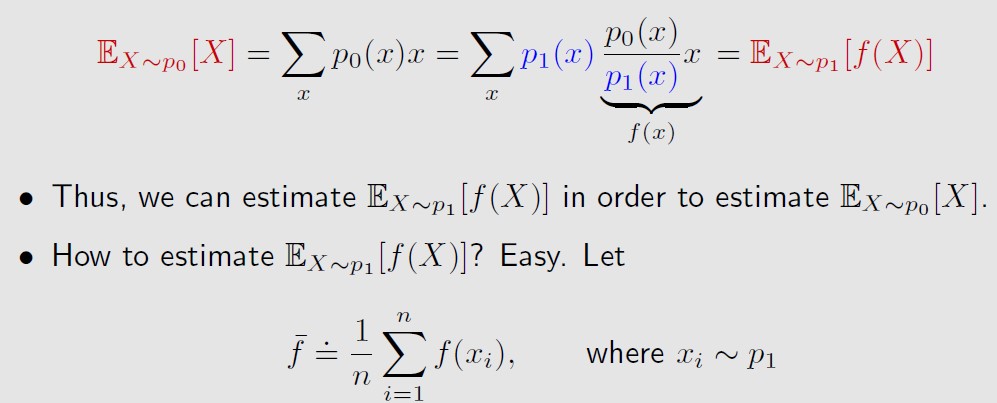
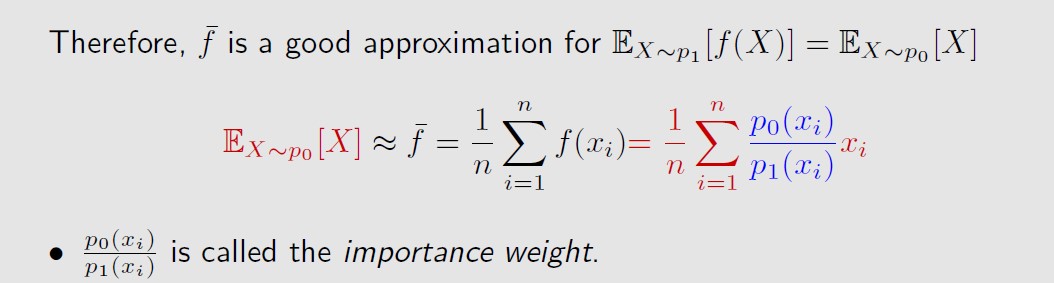
也就是对xi的加权平均,权重为p0/p1,被称为重要性权重 。
重要性权重的计算需要我们知道p0(xi)和p1(xi),如果我们已知知道p0,不就可以
直接算出服从p0分布的x的期望了吗,在有些情况下是不能的:

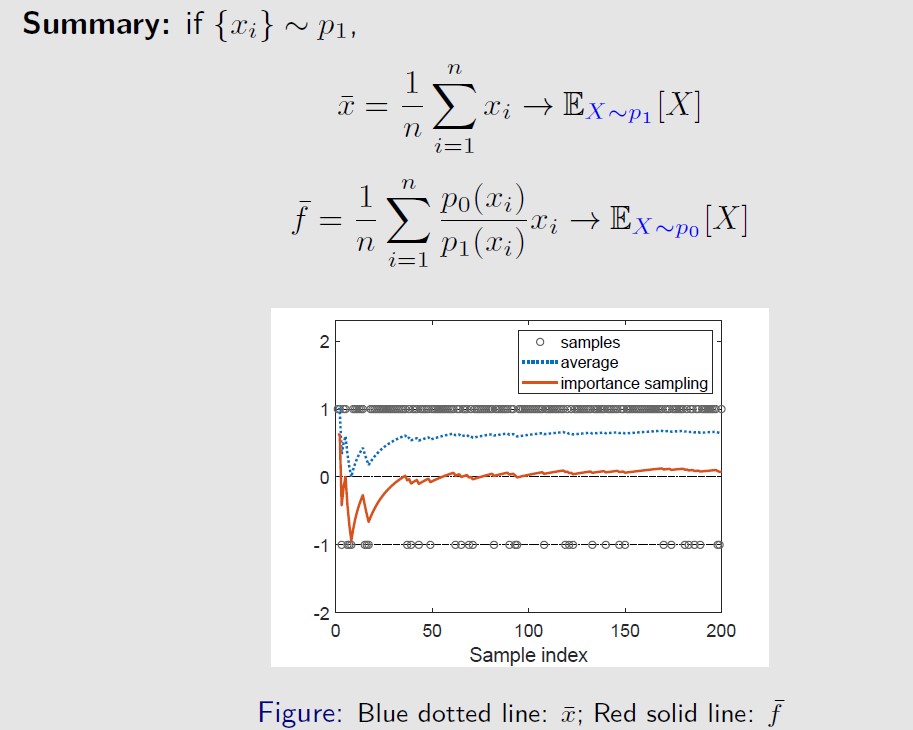
将importance sampling应用,得到off policy gradient

和on policy A2C一样,可以加入一个偏置b(s)来降低估计的方差


可以看出,当t大的时候,步长大,下一步更新后会(at)会变大,相当于是expolitation,![]()
充分利用,但是和on policy相比,分母不是了,而是,是固定的,所以没有explore,![]()
没有探索。

算法和on policy基本是一样的,队了在poilcy update 和value update中加入了
importance weight。