CS336-2025-lec3-4
2025年10月21日
16:15
z-loss:通过约束logits的l2范数来防止数值爆炸,从而提升训练过程的稳定性。
lec4-MOE
将原来的一个FFN层换成多个稀疏激活的FFN层,通过router来稀疏激活子FFN层,这样的好处是在同样FLOPS下可以拥有更多的参数量。
多个paper的实验表明 ,MOE比DENSE架构训练效果更好。
MOE在系统设计上更容易并行。
Moe存在的问题:
1)只有在多节点训练时,MOE架构才有优势。
2)路由决策是不可微分 的,因此优化时,即梯度反向传播时,存在困难,必须仔细设计这部分。
通常的做法是对ffn层做moe设计,但是也有对attention层做moe的,但是这样训练更不稳定。
- Routing function
通常的做法是每个token选择topk个expert,少见的做法是每个expert选择topk个token。有paper的消融实验表明,token choice routing 效果好于expert choice routing(expert choice routing的好处是每个专家都会被分到数量均等的token,这在专家并行时很重要,避免token都被分到一个GPU上)。
其他Routing方法:
对于Router,可以是一个单层MLP,x*W,经过softmax,得到k个expert的权重 。也可以是一个hash函数,不需要训练,根据hash函数分配token到不同的Expert上。
还有RL routing,因为routing是个离散的过程,RL适合解决离散的问题。
还有的通过solve a matching problem来做routing。

上图是token choice routing,计算每个expert的权重时,类似于计算attention得分,将token embedding u和专家embedding e 做点积,然后softmax归一化(注意,只对topk个专家进行softmax,而不是对所有专家),得到权重 。
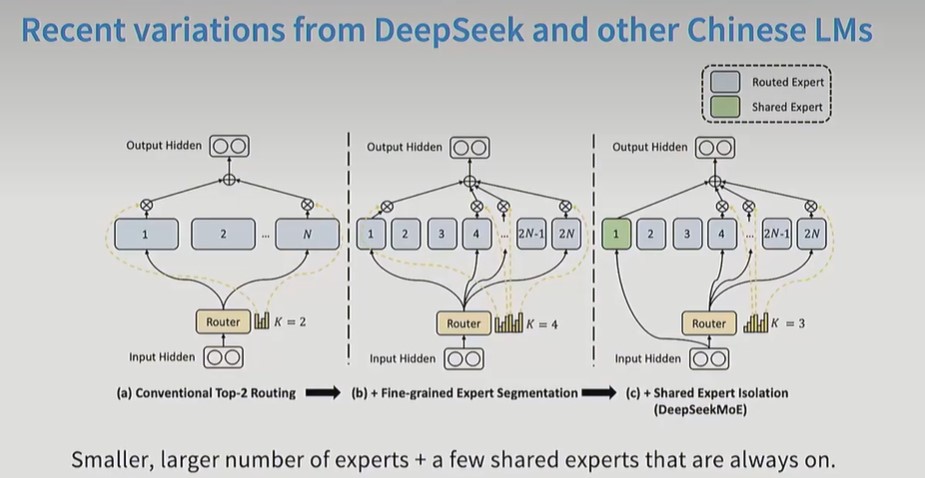
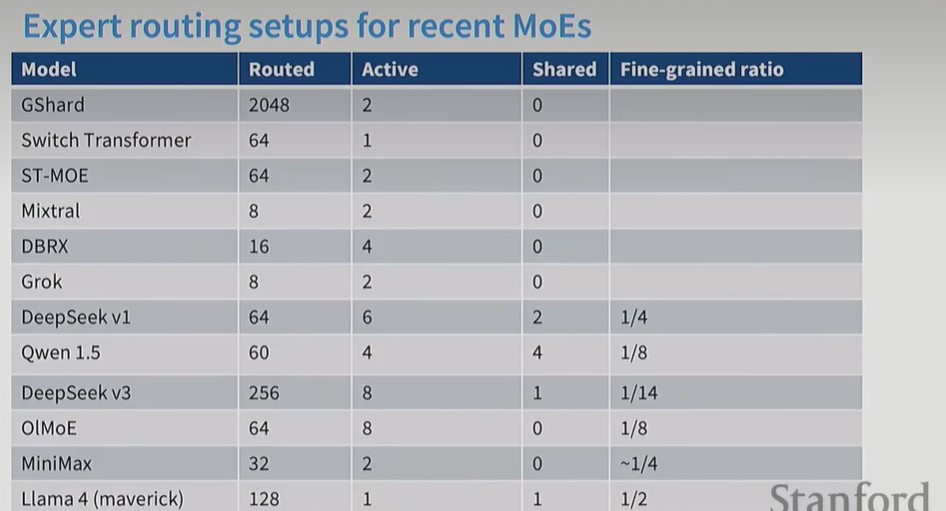
Deepseek v3 moe:细粒度专家+共享专家。细粒度指的是每个专家的参数量变小,专家数量变多
- Expert sizes
- Training objectives
Sparse gating decisions are not differentiable
- RL-效果一般
- stochastic perturbations
- heuristic balancing loss

通过设计balanced loss学习router 函数,让tokens被均匀分配到不同的专家或GPU上。
Deepseek v3 通过在线学习,调整每个expert的b_i。如果这个专家很受欢迎,就降低它的bi,如果不受欢迎,就提高它的bi

如果不做专家balanced loss,那么实际上只有1-2个专家被一直激活,其他专家都没有用。
Moe存在的问题
MOE存在训练不稳定的问题,解决方法是用float32,并且加入z-loss,以及上面提到的expert balanced loss.

另一个问题是,moe在finetuning时容易过拟合,解决方法是可以用dense和moe层交替的架构 ,也可以增加训练数据。