CS336-2025-lec7
2025年10月23日
16:45
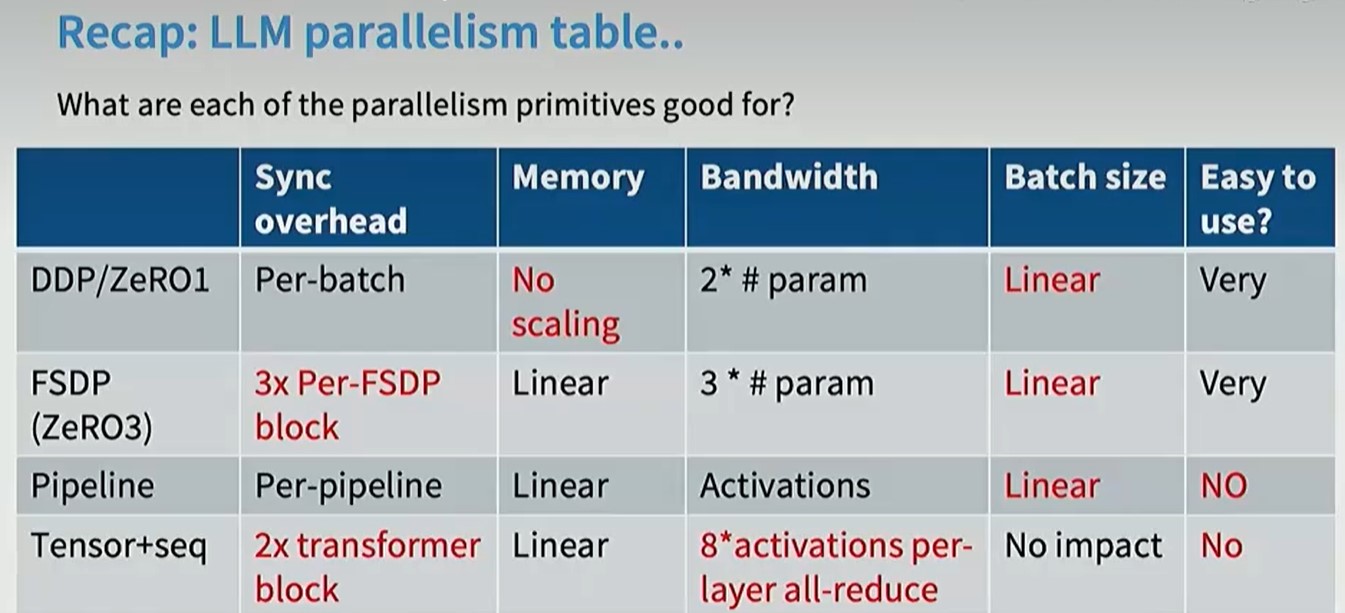
并行
- 数据并行(不同GPU拥有同一个模型,不切分模型参数,而是切分同一个batch,每个GPU获得同一个batch的不同部分)
- Naïve data parallel
- ZERO LEVEL 1-3
- 模型并行(不同GPU拥有模型的不同部分)
- Pipeline parallel
- Tensor parallel
- Activation parallel
- Sequential parallel
通过并行,我们想实现什么?1)Linear memory scaling,模型的参数量随着GPU的增加可以线性增加,如一个GPU可以容纳16G的模型,通过并行,使得2个GPU能容纳32G的模型。2)Linear compute scaling,模型的计算量随着GPU增加线性增加。
Data parallel

Naïve data palrallel就是将Bacth数据分为M份到M个GPU上,然后在梯度更新时,对参数梯度进行同步。compute scaling是线性。通信成本需要进行all reduce操作,成本是2倍的模型参数量。

Naïve data palrallel的问题在于memory 占用,每个GPU上除了存储模型参数,还需要存储gradients, master weights, 一阶估计,二阶估计,关键是这些参数在所有的GPU上都是重复的,总的内存占用是随着GPU数量增加线性增加的。

最占用显存的是optimizer states,我们需要在所有GPU上同时拥有参数和梯度,但是我们需要所有GPU上都拥有全部的optimizer state吗?
上图第二行,Pos, 通过optimizer sharding,可以降低总内存占用至31GB
上图第3行,Pos+g,在Pos的基础上,对gradient也进行sharding
上图第4行,Pos+g+p,在上面的基础上,对parameter也进行sharding。

ZERO stage1,只对optimizer 进行sharding,每个gpu拥有全部的参数和梯度,但只拥有部分的optimizer state,训练时,每个GPU用不同数据训练后得到所有参数的梯度,然后进行梯度同步,然后每个GPU只对自己拥有的optimizer state的那部分参数进行更新,然后再进行参数同步。
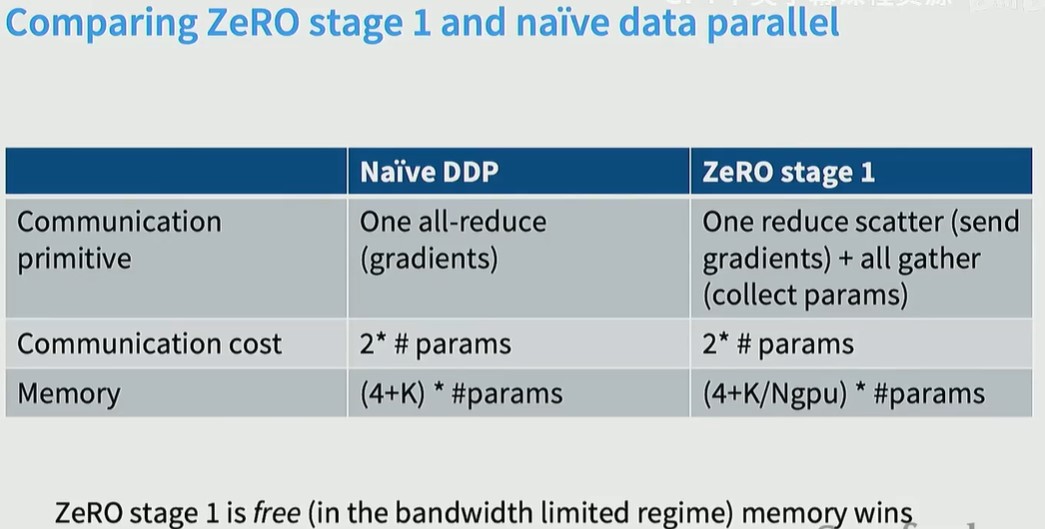
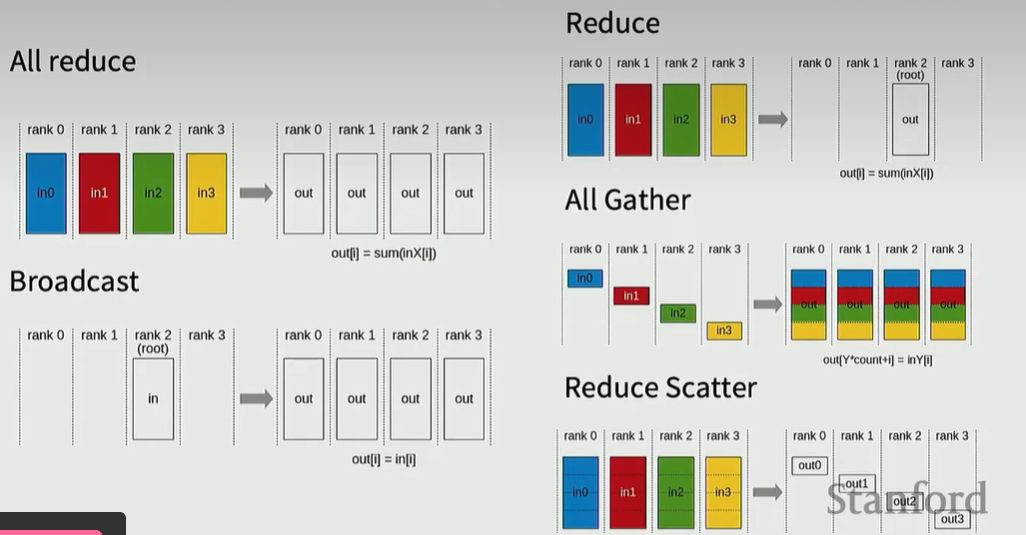
ZERO stage1的通信成本(一次reduce scatter 和一次all gather)和Naïve DDP(一次all reduce)是一样的,但是memory节省了很多。
ZERO stage2,对梯度进行shard,每个GPU拥有一部分参数的梯度
ZERO stage3,FSDP,对参数也进行shard
总之,shard的东西越多,也就需要增加相应的通信成本。

Model parallel
- Pipeline parallel
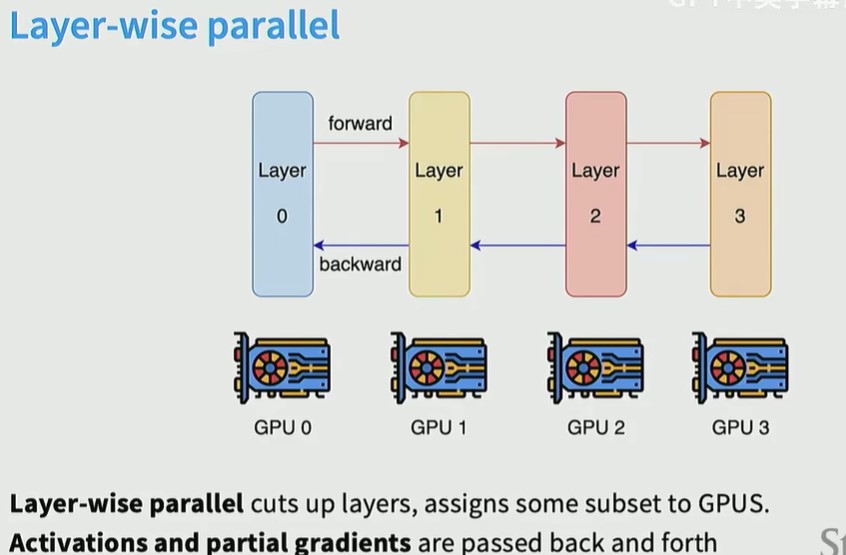
Layer-wise 并行的缺点是,GPU利用率低,必须等其他GPU计算完成后,当前GPU才能开始计算,
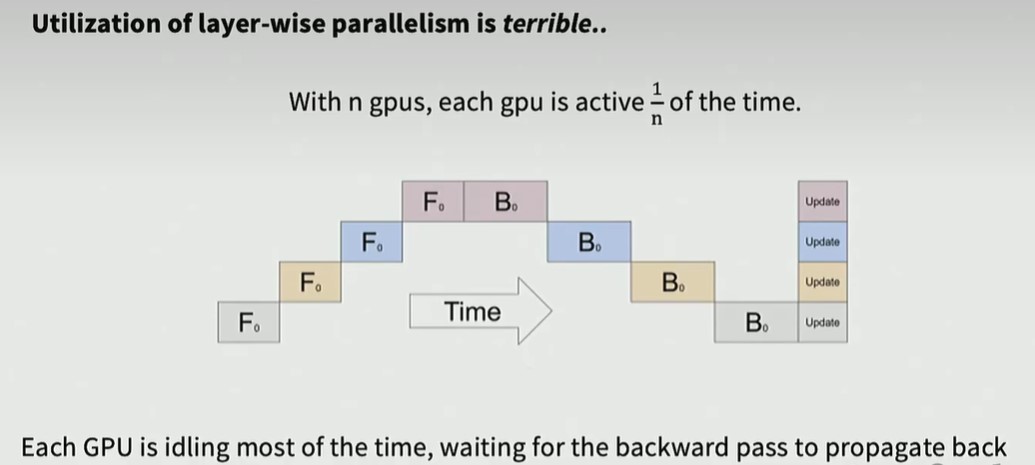
解决方案是一次处理一个bacth,而不是一个样本,GPU0处理完当前样本后,马上开始处理下一个样本,这样,中间bubble的空闲时间变少了。
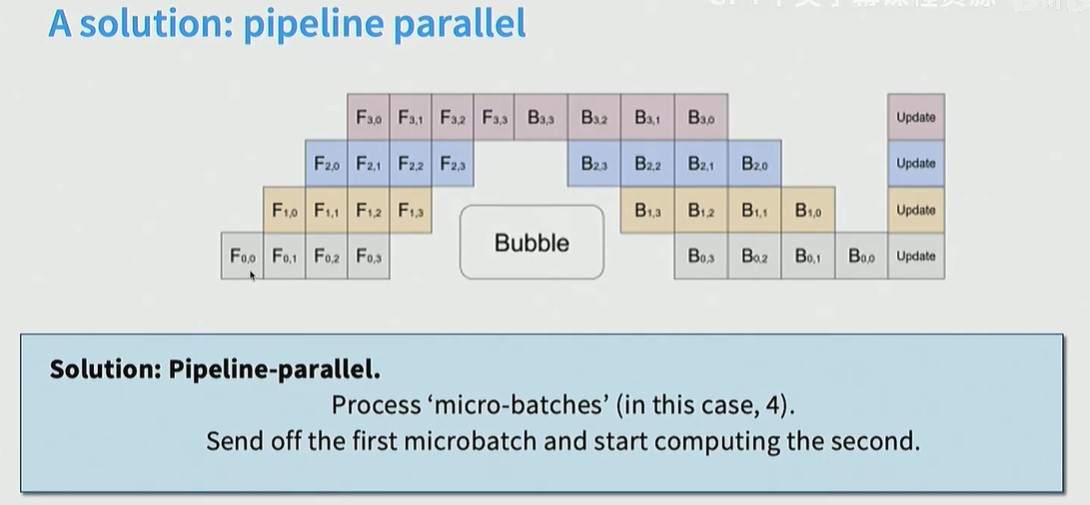
- Tensor parallel
将大矩阵分成多个小矩阵。和layerwise不同,每个GPU都有模型的所有层,但是只有层的一部分
总结: